
Last updated: June 2026
Introduction
Moving data between Google BigQuery and PostgreSQL traditionally involves complex ETL processes, custom scripts, and significant engineering effort. Organizations often face challenges such as:
- Setting up and maintaining data extraction processes from BigQuery
- Managing authentication and permissions across platforms
- Handling schema compatibility and data type conversions
- Implementing efficient data loading into PostgreSQL
- Monitoring and maintaining the data pipeline
- Dealing with incremental updates and schema changes
According to industry research, setting up a traditional data pipeline between BigQuery and PostgreSQL can take weeks or even months, requiring specialized knowledge of both platforms and custom code development. Common approaches include:
- Writing custom Python scripts using libraries like
pandasandsqlalchemy - Using ETL tools that require extensive configuration and maintenance
- Implementing Apache Airflow DAGs with custom operators
- Developing and maintaining complex data transformation logic
These approaches often lead to:
- Increased development and maintenance costs
- Complex error handling and retry mechanisms
- Difficulty in handling schema changes
- Performance bottlenecks
- Limited monitoring and observability
Sling simplifies this entire process by providing a streamlined, configuration-based approach that eliminates the need for custom code and complex infrastructure setup. With Sling, you can:
- Configure connections with simple environment variables or CLI commands
- Automatically handle schema mapping and data type conversions
- Optimize performance with built-in batch processing and parallel execution
- Monitor and manage replications through both CLI and web interface
- Implement incremental updates with minimal configuration
In this guide, we’ll walk through the process of setting up a BigQuery to PostgreSQL replication using Sling, demonstrating how to overcome common challenges and implement an efficient data pipeline in minutes rather than days or weeks. If you need the opposite direction, our MySQL to BigQuery guide and Postgres to BigQuery guide cover loading into BigQuery.
Installation
Getting started with Sling is straightforward. You can install it using various package managers depending on your operating system:
# macOS / Linux
curl -fsSL https://slingdata.io/install.sh | bash
# Windows
irm https://slingdata.io/install.ps1 | iex
# Python
pip install sling
After installation, verify that Sling is properly installed by running:
# Check sling version
sling --version
For more detailed installation instructions and options, visit the installation guide.
Setting Up Connections
Before we can start replicating data, we need to configure our source (BigQuery) and target (PostgreSQL) connections. Sling provides multiple ways to manage connections, including environment variables, the sling conns command, and a YAML configuration file.
BigQuery Connection Setup
The BigQuery source connection here is identical to the one used when BigQuery is the source in other pipelines, such as BigQuery to Snowflake.
For BigQuery, you’ll need:
- Google Cloud project ID
- Service account credentials with appropriate permissions
- Dataset information
- Google Cloud Storage bucket (for data transfer)
You can set up the BigQuery connection in several ways:
- Using the
sling conns setCommand
# Set up BigQuery connection using CLI
sling conns set bigquery_source type=bigquery \
project=<project> \
dataset=<dataset> \
gc_bucket=<gc_bucket> \
key_file=/path/to/service.account.json \
location=<location>
- Using Environment Variables
# Set up using service account JSON content
export GC_KEY_BODY='{"type": "service_account", ...}'
export BIGQUERY_SOURCE='{type: bigquery, project: <project>, dataset: <dataset>, gc_bucket: <gc_bucket>}'
- Using Sling Environment YAML
Create or edit ~/.sling/env.yaml:
connections:
bigquery_source:
type: bigquery
project: your-project
dataset: your_dataset
gc_bucket: your-bucket
key_file: /path/to/service.account.json
location: US # optional
PostgreSQL Connection Setup
For PostgreSQL, you’ll need:
- Host address
- Port number (default: 5432)
- Database name
- Username and password
- Schema (optional)
- SSL mode (if required)
Here’s how to set up the PostgreSQL connection:
- Using the
sling conns setCommand
# Set up PostgreSQL connection using CLI
sling conns set postgres_target type=postgres \
host=<host> \
user=<user> \
database=<database> \
password=<password> \
port=<port> \
schema=<schema>
# Or use connection URL format
sling conns set postgres_target url="postgresql://user:password@host:5432/database?sslmode=require"
- Using Environment Variables
# Set up using connection URL format
export POSTGRES_TARGET='postgresql://user:password@host:5432/database?sslmode=require'
- Using Sling Environment YAML
Add to your ~/.sling/env.yaml:
connections:
postgres_target:
type: postgres
host: your-host
user: your-username
password: your-password
database: your-database
port: 5432
schema: public
sslmode: require # optional
Testing Connections
After setting up your connections, it’s important to verify they work correctly:
# Test BigQuery connection
sling conns test bigquery_source
# Test PostgreSQL connection
sling conns test postgres_target
# List available tables in BigQuery
sling conns discover bigquery_source
You can also manage your connections through the Sling Platform’s web interface:

For more details about connection configuration, visit the environment documentation.
Data Replication Methods
Sling provides multiple ways to replicate data from BigQuery to PostgreSQL. Let’s explore both CLI-based and YAML-based approaches, starting from simple configurations to more advanced use cases.
Using CLI Flags
The quickest way to start a replication is using CLI flags. Here are two examples:
Basic CLI Example
This example shows how to replicate a single table with default settings:
# Replicate a single table from BigQuery to PostgreSQL
sling run \
--src-conn bigquery_source \
--src-stream "analytics.daily_sales" \
--tgt-conn postgres_target \
--tgt-object "analytics.daily_sales" \
--tgt-options '{ "column_casing": "snake" }'
Advanced CLI Example
This example demonstrates more advanced options including column selection and incremental updates:
# Replicate with advanced options
sling run \
--src-conn bigquery_source \
--src-stream "analytics.customer_orders" \
--select "order_id, customer_id, order_date, total_amount" \
--tgt-conn postgres_target \
--tgt-object "analytics.customer_orders" \
--mode incremental \
--primary-key order_id \
--update-key order_date \
--tgt-options '{ "column_casing": "snake", "add_new_columns": true, "table_keys": { "unique": ["order_id"] } }'
For more CLI flag options, visit the CLI flags documentation.
Using YAML Configuration
For more complex replication scenarios, YAML configuration files provide better maintainability and reusability. Let’s look at two examples:
Basic YAML Example
Create a file named bigquery_to_postgres.yaml:
# Define source and target connections
source: bigquery_source
target: postgres_target
# Default settings for all streams
defaults:
mode: full-refresh
target_options:
column_casing: snake
add_new_columns: true
# Define streams to replicate
streams:
analytics.daily_sales:
object: analytics.daily_sales
primary_key: [date, product_id]
analytics.customer_orders:
object: analytics.{stream_table}
primary_key: order_id
Run the replication:
# Run the replication using YAML config
sling run -r bigquery_to_postgres.yaml
Advanced YAML Example
Here’s a more complex example that demonstrates various features including runtime variables, custom SQL, and multiple streams:
source: bigquery_source
target: postgres_target
env:
DATE: ${DATE} # from env var
defaults:
mode: incremental
target_options:
column_casing: snake
add_new_columns: true
streams:
# Stream with custom SQL and runtime variables
analytics.orders_{DATE}:
object: analytics.orders
sql: |
SELECT *
FROM analytics.orders
WHERE DATE(created_at) = '{DATE}'
primary_key: order_id
update_key: updated_at
# Stream with column selection and transforms
analytics.customers:
object: analytics.customers
select:
- customer_id
- first_name
- last_name
- email
- -internal_notes # exclude this column
transforms:
email: [lower, trim]
primary_key: customer_id
target_options:
table_keys:
primary: [customer_id]
unique: [email]
# Stream with wildcard pattern
analytics.events_*:
object: analytics.events
mode: full-refresh
primary_key: event_id
Run the replication with runtime variables:
# Run the replication with a specific date
export DATE=2024-02-10
sling run -r bigquery_to_postgres.yaml
For more details about replication configuration, visit:
Sling Platform UI
While the CLI provides powerful functionality for local development and automation, the Sling Platform offers a comprehensive web interface for managing and monitoring your data replications at scale.
Platform Overview
The Sling Platform provides:
- Visual interface for creating and managing data workflows
- Team collaboration features
- Monitoring and alerting
- Centralized connection management
- Job scheduling and orchestration
- Agent-based architecture for secure execution
Managing Connections
The platform provides an intuitive interface for managing your connections:
You can:
- Create and edit connections with a visual form
- Test connections directly from the UI
- View and manage connection permissions
- Share connections with team members
Visual Replication Editor
The platform includes a powerful visual editor for creating and managing replications:

Features include:
- Visual stream configuration
- Syntax highlighting for SQL and YAML
- Real-time validation
- Version control integration
Monitoring and Execution
Track your replication jobs with detailed execution information:
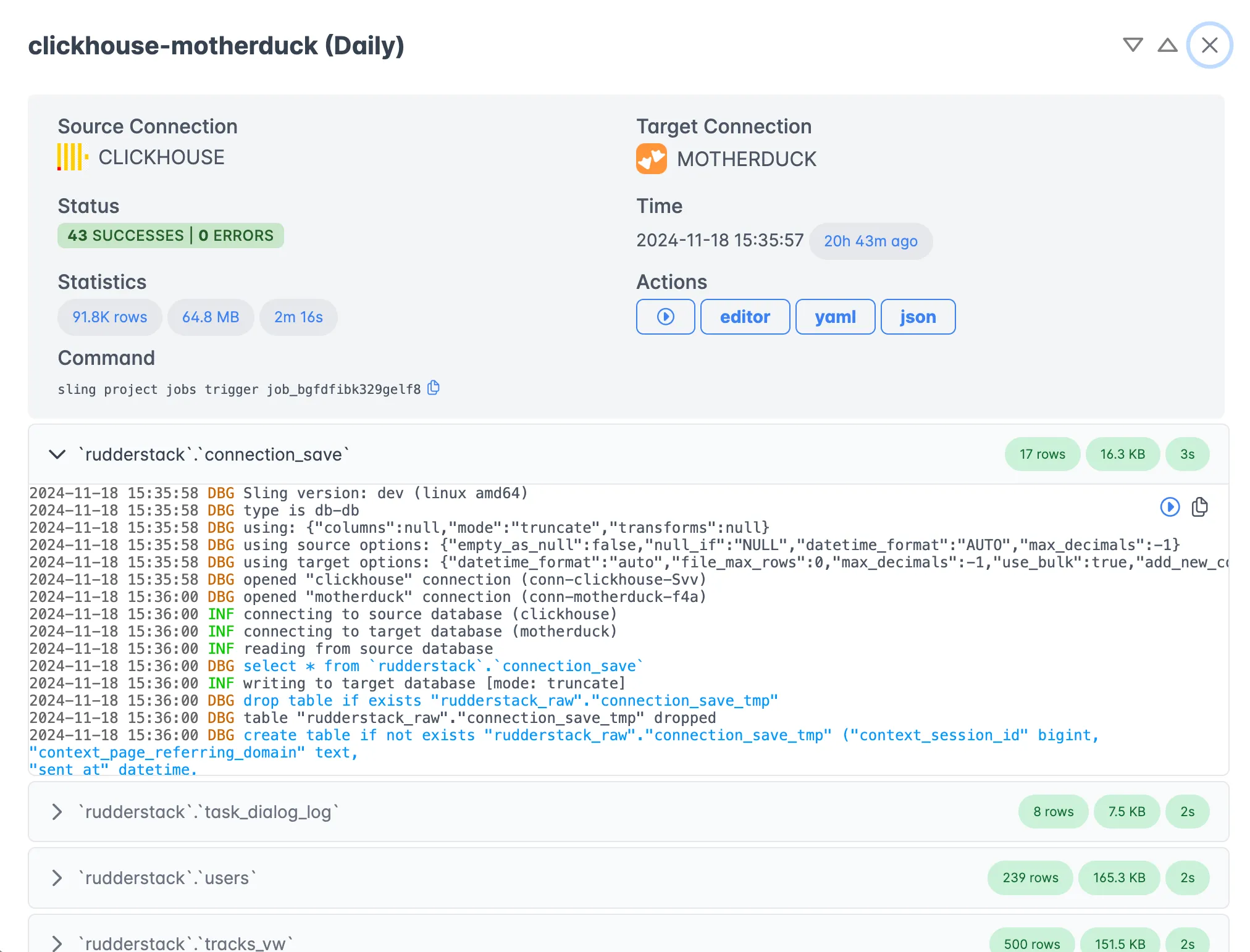
The platform provides:
- Real-time execution monitoring
- Detailed logs and error messages
- Performance metrics and statistics
- Historical execution data
For more information about the Sling Platform, visit the platform documentation.
Getting Started
Now that we’ve covered the various aspects of using Sling for BigQuery to PostgreSQL data replication, here’s a quick guide to get you started:
Install Sling
- Choose the appropriate installation method for your system
- Verify the installation with
sling --version
Set Up Connections
- Configure BigQuery source connection
- Configure PostgreSQL target connection
- Test both connections using
sling conns test
Start Simple
- Begin with a basic CLI command to replicate a single table
- Monitor the replication process
- Verify the data in PostgreSQL
Scale Up
- Create a YAML configuration file for multiple streams
- Add incremental updates and transformations
- Implement runtime variables for flexibility
Consider Platform Features
- Sign up for the Sling Platform for advanced features
- Set up team access and permissions
- Configure monitoring and alerts
Best Practices
Connection Management
- Use environment variables or YAML files for connection configuration
- Keep credentials secure and never commit them to version control
- Use separate connections for development and production
Replication Configuration
- Start with simple configurations and gradually add complexity
- Use YAML files for better maintainability
- Document your configurations with clear descriptions
Performance Optimization
- Use appropriate batch sizes for your data volume
- Implement incremental updates when possible
- Monitor and adjust configurations based on performance metrics
Monitoring and Maintenance
- Regularly check replication logs
- Set up alerts for failed replications
- Keep Sling updated to the latest version
Next Steps
Once your data lands in Postgres, you can keep moving it downstream; see Postgres to DuckDB for fast local analytics or loading JSON data into Postgres for the file-to-Postgres direction.
To learn more about Sling’s capabilities, explore these resources:
For additional examples and community support:
- Join the Sling Discord Community
- Follow Sling on GitHub
- Contact [email protected] for assistance
FAQ
How do I export a BigQuery table to PostgreSQL with Sling?
Set bigquery as the source connection and postgres as the target, then point a stream’s object key at the destination schema and table. A single sling run command moves the data, creating the target table if it does not exist.
Can I run incremental loads from BigQuery into Postgres?
Yes. Set mode to incremental on the stream and supply a primary key plus an update_key. Sling compares the update_key against the existing target rows and loads only newer records.
How do I filter BigQuery rows before loading into Postgres?
Add a sql key to the stream with a SELECT statement. The query runs against BigQuery and only the result set is loaded, which is handy for date-partitioned or filtered extracts.
Does Sling automatically convert BigQuery data types to Postgres types?
Yes. Sling maps each BigQuery column to a compatible Postgres type during the load. Enable adjust_column_type under target_options if you want it to widen existing target columns when needed.
How do I set a primary key or unique constraint on the Postgres target?
Use a table_keys block under target_options with primary and unique lists, for example primary: [customer_id] and unique: [email]. Sling applies these keys when it creates or maintains the target table.
Can I use runtime variables like a date in the replication config?
Yes. Reference variables with single braces such as {DATE} in object names, stream names, or SQL, and pass the value through the env block or an environment variable at run time.
What permissions does the BigQuery service account need?
It needs read access to the source dataset and read/write access to the GCS bucket set as gc_bucket, since Sling stages data through Cloud Storage during extraction.