
Introduction
Last updated: June 2026
Moving data between cloud data warehouses like Google BigQuery and Snowflake traditionally involves complex ETL processes, custom scripts, and significant engineering effort. Organizations often face challenges such as:
- Setting up and maintaining data extraction processes from BigQuery
- Managing authentication and permissions across platforms
- Handling schema compatibility and data type conversions
- Implementing efficient data loading into Snowflake
- Monitoring and maintaining the data pipeline
- Dealing with incremental updates and schema changes
According to industry research, setting up a traditional data pipeline between BigQuery and Snowflake can take weeks or even months, requiring specialized knowledge of both platforms and custom code development. This complexity often leads to increased costs, maintenance overhead, and potential reliability issues.
Sling simplifies this entire process by providing a streamlined, configuration-based approach that eliminates the need for custom code and complex infrastructure setup. With Sling, you can:
- Configure connections with simple environment variables or CLI commands
- Automatically handle schema mapping and data type conversions
- Optimize performance with built-in batch processing and parallel execution
- Monitor and manage replications through both CLI and web interface
- Implement incremental updates with minimal configuration
In this guide, we’ll walk through the process of setting up a BigQuery to Snowflake replication using Sling, demonstrating how to overcome common challenges and implement an efficient data pipeline in minutes rather than days or weeks. If you need to move data the other direction, see the guide on exporting Snowflake to BigQuery.
Installation
Getting started with Sling is straightforward. You can install it using various package managers depending on your operating system:
# macOS / Linux
curl -fsSL https://slingdata.io/install.sh | bash
# Windows
irm https://slingdata.io/install.ps1 | iex
# Python
pip install sling
After installation, verify that Sling is properly installed by running:
# Check sling version
sling --version
For more detailed installation instructions and options, visit the installation guide.
Setting Up Connections
Before we can start replicating data, we need to configure our source (BigQuery) and target (Snowflake) connections. Sling provides multiple ways to manage connections, including environment variables, the sling conns command, and a YAML configuration file.
BigQuery Connection Setup
For BigQuery, you’ll need:
- Google Cloud project ID
- Service account credentials with appropriate permissions
- Dataset information
- Google Cloud Storage bucket (for data transfer)
You can set up the BigQuery connection in several ways:
- Using the
sling conns setCommand
# Set up BigQuery connection using CLI
sling conns set bigquery_source type=bigquery \
project=<project> \
dataset=<dataset> \
gc_bucket=<gc_bucket> \
key_file=/path/to/service.account.json \
location=<location>
- Using Environment Variables
# Set up using service account JSON content
export GC_KEY_BODY='{"type": "service_account", ...}'
export BIGQUERY_SOURCE='{type: bigquery, project: <project>, dataset: <dataset>, gc_bucket: <gc_bucket>}'
- Using Sling Environment YAML
Create or edit ~/.sling/env.yaml:
connections:
bigquery_source:
type: bigquery
project: your-project
dataset: your_dataset
gc_bucket: your-bucket
key_file: /path/to/service.account.json
location: US # optional
Snowflake Connection Setup
For Snowflake, you’ll need:
- Account identifier (e.g.,
xy12345.us-east-1) - Username and password
- Database name
- Warehouse name
- Role (optional)
- Schema (optional)
Here’s how to set up the Snowflake connection:
- Using the
sling conns setCommand
# Set up Snowflake connection using CLI
sling conns set snowflake_target type=snowflake \
account=<account> \
user=<user> \
password=<password> \
database=<database> \
warehouse=<warehouse> \
role=<role>
- Using Environment Variables
# Set up using connection URL format
export SNOWFLAKE_TARGET='snowflake://user:password@account/database?warehouse=compute_wh&role=sling_role'
- Using Sling Environment YAML
Add to your ~/.sling/env.yaml:
connections:
snowflake_target:
type: snowflake
account: xy12345.us-east-1
user: your_username
password: your_password
database: your_database
warehouse: compute_wh
role: sling_role # optional
schema: public # optional
Testing Connections
After setting up your connections, it’s important to verify they work correctly:
# Test BigQuery connection
sling conns test bigquery_source
# Test Snowflake connection
sling conns test snowflake_target
# List available tables in BigQuery
sling conns discover bigquery_source
You can also manage your connections through the Sling Platform’s web interface:

For more details about connection configuration, visit the environment documentation.
Data Replication Methods
Sling provides multiple ways to replicate data from BigQuery to Snowflake. Let’s explore both CLI-based and YAML-based approaches, starting from simple configurations to more advanced use cases.
Using CLI Flags
The quickest way to start a replication is using CLI flags. Here are two examples:
Basic CLI Example
This example shows how to replicate a single table with default settings:
# Replicate a single table from BigQuery to Snowflake
sling run \
--src-conn bigquery_source \
--src-stream "analytics.daily_sales" \
--tgt-conn snowflake_target \
--tgt-object "ANALYTICS.DAILY_SALES" \
--tgt-options '{ "column_casing": "upper" }'
Advanced CLI Example
This example demonstrates more advanced options including column selection and data type handling:
# Replicate with advanced options
sling run \
--src-conn bigquery_source \
--src-stream "analytics.customer_orders" \
--select "order_id, customer_id, order_date, total_amount" \
--tgt-conn snowflake_target \
--tgt-object "ANALYTICS.CUSTOMER_ORDERS" \
--mode incremental \
--primary-key order_id \
--update-key order_date \
--tgt-options '{ "column_casing": "upper", "add_new_columns": true }'
For more CLI flag options, visit the CLI flags documentation.
Using YAML Configuration
For more complex replication scenarios, YAML configuration files provide better maintainability and reusability. Let’s look at two examples:
Basic YAML Example
Create a file named bigquery_to_snowflake.yaml:
# Define source and target connections
source: bigquery_source
target: snowflake_target
# Default settings for all streams
defaults:
mode: full-refresh
target_options:
column_casing: upper
add_new_columns: true
# Define the streams to replicate
streams:
# Replicate multiple tables using wildcards
"analytics.*":
object: "ANALYTICS.{stream_table}"
# Replicate a specific table with custom settings
"sales.transactions":
object: "SALES.TRANSACTIONS"
mode: incremental
primary_key: ["transaction_id"]
update_key: "transaction_date"
Advanced YAML Example
Here’s a more complex configuration with multiple streams and custom options:
source: bigquery_source
target: snowflake_target
env:
run_date: ${RUN_DATE}
defaults:
mode: incremental
target_options:
column_casing: upper
add_new_columns: true
streams:
# Replicate with custom SQL and column selection
"custom_sales_report":
object: "ANALYTICS.SALES_REPORT"
sql: |
SELECT
o.order_id,
c.customer_name,
p.product_name,
o.quantity,
o.total_amount,
o.order_date
FROM `dataset.orders` o
JOIN `dataset.customers` c ON o.customer_id = c.customer_id
JOIN `dataset.products` p ON o.product_id = p.product_id
WHERE o.order_date >= '2023-01-01'
# Replicate with runtime variables and transformations
"daily_metrics":
object: "ANALYTICS.DAILY_METRICS_{run_timestamp}"
sql: |
SELECT
date,
product_category,
SUM(revenue) as total_revenue,
COUNT(DISTINCT customer_id) as unique_customers
FROM `dataset.sales`
WHERE date = '{run_date}'
GROUP BY date, product_category
# Replicate with advanced options
"customer_segments":
mode: truncate
object: "ANALYTICS.CUSTOMER_SEGMENTS"
select: ["segment_id", "segment_name", "created_at", "updated_at"]
To run a replication using a YAML configuration:
# Run the entire replication
sling run -r bigquery_to_snowflake.yaml
# Run specific streams
sling run -r bigquery_to_snowflake.yaml --stream analytics.daily_sales
For more information about runtime variables and configuration options, visit:
Sling Platform Features
While the CLI provides powerful command-line capabilities, the Sling Platform offers a comprehensive web-based solution for managing your data pipelines at scale. Let’s explore some key features that make it easier to manage BigQuery to Snowflake replications.
Visual Configuration Editor
The Sling Platform includes a sophisticated configuration editor that makes it easy to create and modify replication configurations through a user-friendly interface.

The editor provides:
- Syntax highlighting for YAML configurations
- Auto-completion for connection names and options
- Real-time validation of your configuration
- Easy access to documentation and examples
- Version control for configuration changes
Execution Monitoring
Monitor your replications in real-time with detailed execution statistics and logs.
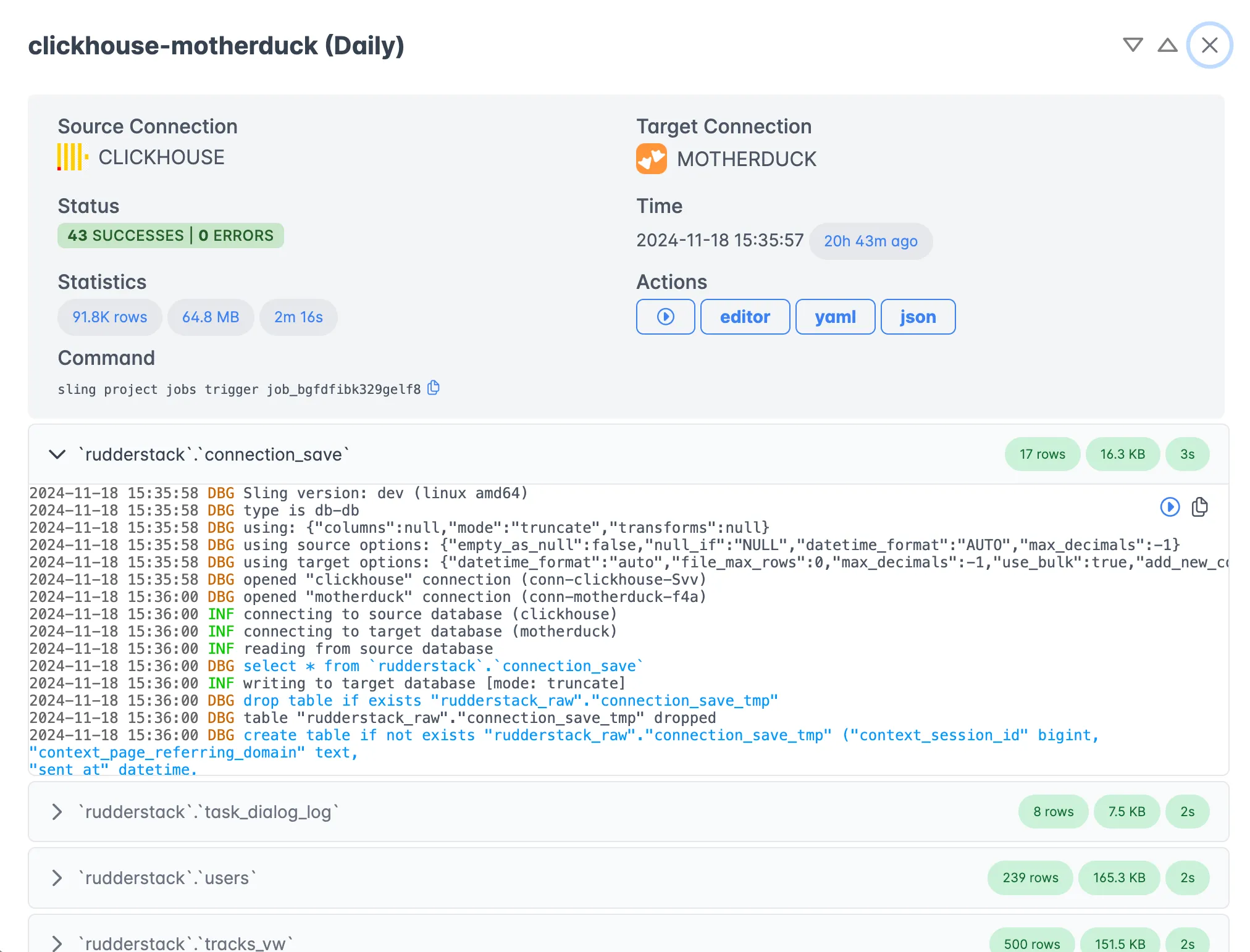
Key monitoring features include:
- Real-time progress tracking
- Detailed execution logs
- Performance metrics and statistics
- Error reporting and diagnostics
- Historical execution data
Team Collaboration
The platform facilitates team collaboration with features such as:
- Role-based access control
- Shared connection management
- Configuration version history
- Team activity monitoring
- Collaborative troubleshooting
Additional Platform Benefits
The Sling Platform offers several advantages for enterprise users:
- Scheduled executions
- Automated retries and error handling
- Integration with notification systems
- Audit logging
- Resource usage monitoring
For more information about the Sling Platform and its features, visit the platform documentation.
Getting Started
Ready to start using Sling for your BigQuery to Snowflake data pipeline? Here’s how to get started:
Set Up Your Environment
- Install Sling CLI
- Configure your connections
- Test connectivity to both platforms
Create Your First Replication
- Start with a simple table replication
- Test the replication process
- Monitor the results
Scale Your Implementation
- Add more tables and transformations
- Implement incremental updates
- Set up scheduling and monitoring
Explore Advanced Features
- Try the Sling Platform
- Implement complex transformations
- Set up team collaboration
Additional Resources
- Database to Database Examples
- Replication Modes Documentation
- Runtime Variables Guide
- Sling Platform Documentation
Related Guides
- Export Snowflake to BigQuery
- Move data from BigQuery to Postgres
- Export SQL Server to BigQuery
- Load Postgres into Snowflake
For more examples and detailed documentation, visit the Sling Documentation.
FAQ
Why does the BigQuery connection need a Google Cloud Storage bucket?
Sling exports BigQuery data through GCS for efficient bulk extraction. It unloads query results to the bucket you set with gc_bucket, then streams them into Snowflake, so the bucket works as a staging area.
How do I match Snowflake’s uppercase identifier convention?
Set column_casing to upper in target_options. Snowflake stores unquoted identifiers in uppercase, so this keeps column and table names lined up with what Snowflake expects.
Can I replicate many BigQuery tables at once?
Yes. Use a wildcard stream such as analytics.* to match every table in a dataset, and reference the {stream_table} runtime variable in the target object so each Snowflake table is named after its source.
How do I run incremental loads from BigQuery to Snowflake?
Set mode to incremental and define table_keys with a primary key plus an update_key. Sling pulls only the rows that changed on each run and merges them into the Snowflake target.
Does Sling create the Snowflake tables, and can it add new columns automatically?
Sling creates target tables that do not exist and infers types from BigQuery. Turn on add_new_columns in target_options so new source columns are added to the Snowflake table instead of breaking the run.
Which Snowflake role and warehouse does Sling use for loading?
Sling uses the warehouse and optional role you set on the Snowflake connection. The role needs permission to create or write to the target schema, and the warehouse has to be able to run the load.