
Introduction
Last updated: June 2026
Cloudflare D1 and DuckDB represent two innovative approaches to database management - D1 as a serverless SQL database integrated with Cloudflare’s edge network, and DuckDB as a high-performance analytical database engine. While both serve distinct purposes, organizations often need to move data between these systems for analytics, reporting, and data processing workflows. This is where Sling comes in, offering a streamlined solution for data migration between these platforms.
What is Cloudflare D1?
Cloudflare D1 is a serverless SQL database that runs at the edge, built on SQLite and integrated seamlessly with Cloudflare Workers. It offers:
- Zero configuration database management
- Automatic replication across Cloudflare’s global network
- SQLite compatibility
- Seamless integration with Cloudflare Workers
- Built-in security and performance optimizations
Understanding DuckDB
DuckDB is an in-process SQL OLAP database management system that excels at analytical queries. Key features include:
- Columnar-vectorized query execution
- Complex query optimization
- Efficient data compression
- Seamless integration with Python and R
- Support for structured and semi-structured data
Introduction to Sling
As an open-source data movement tool, Sling simplifies the process of transferring data between different database systems. It offers:
- Simple installation and configuration
- Multiple replication modes
- Efficient handling of large datasets
- Built-in data type mapping
- Automated schema management
- Real-time monitoring
Getting Started with Sling
Before we dive into replicating data from D1 to DuckDB, let’s set up Sling on your system. Sling offers multiple installation methods to suit different operating systems and preferences.
Installation
Choose the installation method that matches your operating system:
# macOS / Linux
curl -fsSL https://slingdata.io/install.sh | bash
# Windows
irm https://slingdata.io/install.ps1 | iex
# Python
pip install sling
After installation, verify that Sling is properly installed by checking its version:
# Check Sling version
sling --version
Initial Configuration
Sling uses a configuration directory to store connection details and other settings. The configuration directory is typically located at:
- Linux/macOS:
~/.sling/ - Windows:
C:\Users\<username>\.sling\
The first time you run Sling, it will automatically create this directory and a default configuration file. You can also specify a custom location using the SLING_HOME_DIR environment variable.
Understanding Sling’s Architecture
Sling’s architecture is designed for efficient data movement:
Connection Management
- Secure credential storage
- Multiple connection methods support
- Connection pooling and reuse
Data Processing
- Streaming data transfer
- Automatic type conversion
- Configurable batch sizes
Monitoring and Control
- Real-time progress tracking
- Detailed logging
- Error handling and recovery
For more detailed installation instructions and configuration options, visit the Sling CLI Getting Started Guide.
Setting Up Database Connections
Before we can replicate data, we need to configure our source (D1) and target (DuckDB) connections. Sling provides multiple ways to set up and manage connections securely.
Configuring D1 Connection
Cloudflare D1 connections in Sling require your Cloudflare account credentials and database information. Here’s how to set up a D1 connection:
Using Environment Variables
The simplest way is to use environment variables:
# Set D1 connection using environment variable
export D1_SOURCE='d1://account_id:api_token@database_name'
Using the Sling CLI
Alternatively, use the sling conns set command:
# Set up D1 connection with individual parameters
sling conns set D1_SOURCE type=d1 account_id=your_account_id api_token=your_api_token database=your_database_name
# Or use a connection URL
sling conns set D1_SOURCE url="d1://account_id:api_token@database_name"
Using the Sling Environment File
You can also add the connection details to your ~/.sling/env.yaml file:
connections:
D1_SOURCE:
type: d1
account_id: your_account_id
api_token: your_api_token
database: your_database_name
Setting Up DuckDB Connection
DuckDB connections in Sling are straightforward as they primarily involve specifying a file path. Here’s how to set up a DuckDB connection:
Using the Sling CLI
# Set up DuckDB connection
sling conns set DUCKDB type=duckdb path=/path/to/database.duckdb
Using Environment Variables
# Set DuckDB connection using environment variable
export DUCKDB='duckdb:///path/to/database.duckdb'
Using the Sling Environment File
Add to your ~/.sling/env.yaml:
connections:
DUCKDB:
type: duckdb
path: /path/to/database.duckdb
Testing Connections
After setting up your connections, verify them using the sling conns commands:
# List all configured connections
sling conns list
# Test D1 connection
sling conns test D1_SOURCE
# Test DuckDB connection
sling conns test DUCKDB
# Discover available tables in D1
sling conns discover D1_SOURCE
For more details about connection configuration and options, refer to:
Basic Data Replication with CLI
Once you have your connections set up, you can start replicating data from D1 to DuckDB using Sling’s CLI flags. Let’s look at some common usage patterns.
Simple Table Replication
The most basic way to replicate data is using the sling run command with source and target specifications:
# Replicate a single table from D1 to DuckDB
sling run \
--src-conn D1_SOURCE \
--src-stream "users" \
--tgt-conn DUCKDB \
--tgt-object "main.users"
Using Custom SQL Queries
You can use custom SQL queries to transform or filter data during replication:
# Replicate with a custom SQL query
sling run \
--src-conn D1_SOURCE \
--src-stream "SELECT id, name, email, created_at FROM users WHERE created_at > '2024-01-01'" \
--tgt-conn DUCKDB \
--tgt-object "main.recent_users"
Advanced CLI Options
For more complex scenarios, you can use additional flags to customize the replication:
# Replicate with specific columns and options
sling run \
--src-conn D1_SOURCE \
--src-stream "orders" \
--tgt-conn DUCKDB \
--tgt-object "main.orders" \
--select "id,customer_id,total_amount,status" \
--mode incremental \
--update-key "updated_at" \
--tgt-options '{ "add_new_columns": true, "table_keys": { "primary": ["id"] } }'
For a complete list of available CLI flags and options, refer to the Sling CLI Flags documentation.
Advanced Replication with YAML
While CLI flags are great for simple operations, YAML configurations provide more flexibility and maintainability for complex replication scenarios. Let’s explore how to use YAML configurations for D1 to DuckDB data replication.
Understanding YAML Configuration Structure
A typical replication YAML file includes source and target connections, along with stream definitions. Here’s a basic example:
# Basic replication configuration
source: D1_SOURCE
target: DUCKDB
streams:
main.users:
object: main.users
mode: full-refresh
Multiple Stream Replication
You can configure multiple streams in a single YAML file:
# Multiple stream replication
source: D1_SOURCE
target: DUCKDB
defaults:
mode: incremental
target_options:
add_new_columns: true
column_casing: snake
table_keys:
primary: [id]
streams:
users:
object: main.users
update_key: updated_at
source_options:
datetime_format: YYYY-MM-DD HH:mm:ss
orders:
object: main.orders
update_key: order_date
select: [id, customer_id, order_date, total_amount, status]
customers:
object: main.customers
mode: full-refresh
source_options:
empty_as_null: true
Using Runtime Variables
Sling supports runtime variables that can be used in your YAML configurations:
source: D1_SOURCE
target: DUCKDB
env:
SCHEMA: main
TABLE_PREFIX: analytics_
streams:
# Use runtime variables for dynamic table names, load all tables in schema
main.*:
object: '{SCHEMA}.{TABLE_PREFIX}{stream_table}'
mode: incremental
primary_key: id
update_key: updated_at
Configuring Source and Target Options
You can specify various options for both source and target connections:
source: D1_SOURCE
target: DUCKDB
streams:
analytics_data:
object: main.analytics
mode: incremental
update_key: event_date
# Source-specific options
source_options:
datetime_format: YYYY-MM-DD HH:mm:ss
empty_as_null: true
# Target-specific options
target_options:
add_new_columns: true
column_casing: snake
table_keys:
primary: [id]
unique: [event_id]
To run a replication using a YAML configuration:
# Run replication using YAML config
sling run -r d1_to_duckdb_basic.yaml
For more information about YAML configurations, refer to:
Sling Platform Overview
While the CLI is powerful for local development and simple workflows, the Sling Platform provides a comprehensive web-based interface for managing your data operations at scale. Let’s explore the key components and features of the platform.
Web Interface
The Sling Platform offers an intuitive web interface for managing your data operations:

The web interface provides:
- Visual replication editor
- Real-time validation
- Syntax highlighting
- Auto-completion
- Version control integration
Connection Management
Manage all your connections in one place:

The platform offers:
- Centralized credential management
- Connection health monitoring
- Easy testing and validation
- Team access controls
Monitoring and Logging
Track your data operations in real-time:
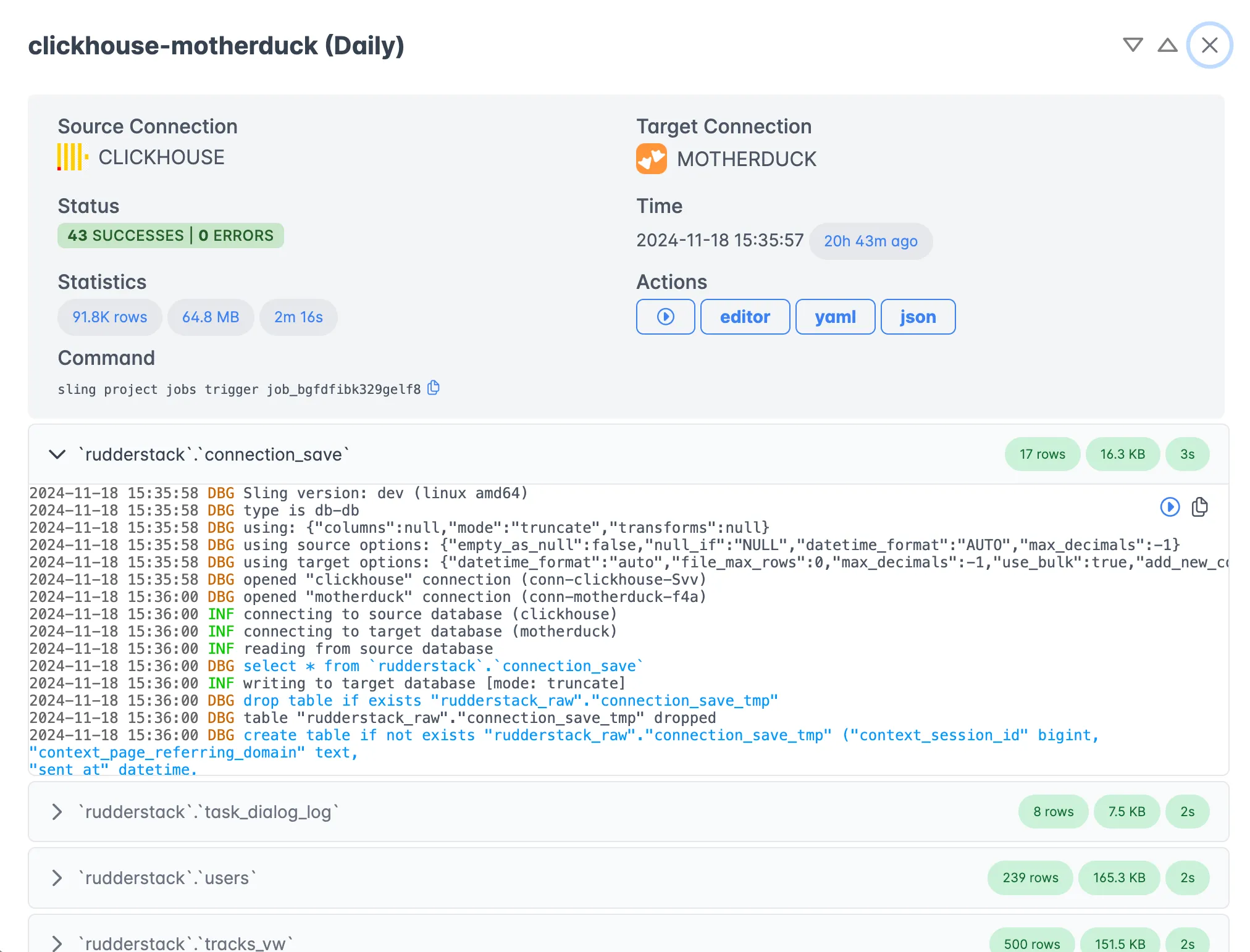
Features include:
- Real-time progress tracking
- Detailed execution logs
- Performance metrics
- Error reporting and alerts
For more information about the Sling Platform, visit:
Best Practices and Next Steps
Now that we’ve covered the various aspects of using Sling for D1 to DuckDB data replication, here are some recommended practices and next steps.
Best Practices
Start Small
- Begin with a simple table replication
- Test with a subset of your data
- Validate the results thoroughly
Optimize Performance
- Use appropriate batch sizes
- Consider incremental updates for large tables
- Monitor system resources
- Use efficient SQL queries
Maintain Security
- Use environment variables for credentials
- Implement proper access controls
- Regularly rotate API tokens
- Follow least privilege principle
Version Control
- Keep YAML configurations in version control
- Document your replication setup
- Track changes and updates
- Use descriptive commit messages
Additional Resources
To learn more about Sling and its capabilities:
Documentation
Examples
Community and Support
- Join our Discord community
- Report issues on GitHub
- Contact support at [email protected]
Next Steps
To continue your journey with Sling:
Explore Advanced Features
- Try different replication modes
- Experiment with transformations
- Test various source and target options
Scale Your Operations
- Move to YAML configurations for complex workflows
- Set up monitoring and alerting
- Implement proper error handling
Consider Platform
- Evaluate the Sling Platform for enterprise needs
- Set up agents for distributed processing
- Implement team collaboration workflows
Remember that Sling is continuously evolving with new features and improvements. Stay connected with the community to learn about updates and best practices as they emerge.
Related Guides
If you are working with D1 or DuckDB-style local analytics, these walkthroughs cover adjacent workflows:
- Migrating Data from Cloudflare D1 to MySQL with Sling for loading edge data into a relational target.
- Export Data from Cloudflare D1 to Local Files with Sling when you want CSV, JSON, or Parquet output instead of a database.
- Loading Local Parquet to Postgres with Sling for moving columnar files into a database.
FAQ
Does Sling read directly from Cloudflare D1 or through the HTTP API?
Sling talks to D1 over Cloudflare’s HTTP query API using your account ID and an API token. There is no local socket, so make sure the token has D1 read permission for the database you target.
Why move D1 data into DuckDB instead of querying D1 directly?
D1 is built for transactional edge workloads, while DuckDB is a columnar engine tuned for analytical scans and joins. Copying the data into DuckDB lets you run heavy aggregations locally without adding load to your edge database.
Can I run incremental syncs from D1 to DuckDB?
Yes. Set mode to incremental and provide an update_key such as updated_at, and Sling will only pull rows newer than the last run. Define a primary key under table_keys so updates merge correctly.
Does the target DuckDB file need to exist before the first run?
No. If the path you point the DuckDB connection at does not exist yet, Sling creates the database file on the first replication and adds the target tables automatically.
How does Sling handle SQLite data types coming from D1?
Sling infers column types from the source data and maps them to DuckDB equivalents during loading. You can override casing and column behavior with target_options like column_casing and add_new_columns.
Can I select only a few columns or filter rows during the export?
Yes. Use the select option to limit columns, or pass a full SQL query as the source stream to filter rows with a WHERE clause before they reach DuckDB.