
The Data Pipeline Challenge
Last updated: June 2026
Moving data from MySQL databases to Google Cloud Storage might seem straightforward, but the reality is far more complex. Traditional data pipeline setups require extensive infrastructure configuration, custom ETL code, format conversion logic, and robust error handling. Organizations often spend weeks or months building what should be a simple data movement process.
Common challenges include:
- Infrastructure complexity: Setting up compute resources, managing dependencies, and ensuring scalability
- Format handling: Converting data between different formats (CSV, Parquet, JSON) with proper schema management
- Connection management: Securely handling database credentials and cloud storage authentication
- Monitoring and reliability: Building robust error handling, retry logic, and monitoring systems
- Maintenance overhead: Keeping pipelines updated as schemas evolve and requirements change
According to industry surveys, data engineers spend up to 70% of their time on data preparation and pipeline maintenance rather than actual analysis. This is where Sling transforms the equation.
Sling eliminates these complexities by providing a unified, modern data movement platform that handles MySQL to Google Cloud Storage transfers with simple commands or YAML configurations. What traditionally takes weeks can now be accomplished in minutes.
What is Sling?
Sling is a modern data integration platform designed to simplify data movement between various sources and destinations. It provides both a powerful command-line interface (CLI) and a comprehensive web-based platform for managing data workflows.
Key capabilities that make Sling perfect for MySQL to GCS transfers:
- Universal connectivity: Native support for MySQL databases and Google Cloud Storage
- Format flexibility: Export to CSV, Parquet, JSON, and other formats with built-in optimization
- Simple configuration: Use environment variables, CLI commands, or YAML files
- Production-ready: Built-in error handling, retry logic, and monitoring capabilities
- Scalable execution: Handle everything from small datasets to enterprise-scale transfers
The platform consists of two main components:
- Sling CLI: Direct command-line access perfect for development, automation, and CI/CD integration
- Sling Platform: Web-based interface for visual workflow creation, team collaboration, and centralized management
Installation and Setup
Getting started with Sling is straightforward. Choose the installation method that works best for your environment:
# macOS / Linux
curl -fsSL https://slingdata.io/install.sh | bash
# Windows
irm https://slingdata.io/install.ps1 | iex
# Python
pip install sling
# Verify installation
sling --version
For more detailed installation instructions, visit the Getting Started guide.
Connection Configuration
Sling provides multiple ways to configure your database and storage connections. Let’s set up both MySQL source and Google Cloud Storage target connections.
MySQL Source Connection
Method 1: Environment Variables
# Set MySQL connection as environment variable
export MYSQL_SOURCE='mysql://username:password@localhost:3306/mydb'
# Or using JSON format for more control
export MYSQL_SOURCE='{
"type": "mysql",
"host": "localhost",
"port": 3306,
"user": "username",
"password": "password",
"database": "mydb"
}'
Method 2: Using sling conns set
# Set MySQL connection using individual parameters
sling conns set mysql_source type=mysql host=localhost user=username database=mydb password=mypassword port=3306
# Or using a connection URL
sling conns set mysql_source url="mysql://username:password@localhost:3306/mydb"
Method 3: env.yaml Configuration File
Create an env.yaml file in your project directory:
connections:
mysql_source:
type: mysql
host: localhost
port: 3306
user: username
password: mypassword
database: mydb
# Optional: specify default schema
schema: public
# Alternative URL format
mysql_source_url:
url: "mysql://username:password@localhost:3306/mydb"
Google Cloud Storage Target Connection
Setting up GCS Service Account
Before configuring the GCS connection, ensure you have a Google Cloud service account with appropriate permissions:
- Create a service account in Google Cloud Console
- Grant Storage Object Admin role to your bucket
- Download the JSON key file
Method 1: Environment Variables
# Set GCS connection as environment variable
export GCS_TARGET='{
"type": "gs",
"bucket": "my-data-bucket",
"key_file": "/path/to/service-account-key.json"
}'
Method 2: Using sling conns set
# Set GCS connection
sling conns set gcs_target type=gs bucket=my-data-bucket key_file=/path/to/service-account-key.json
Method 3: env.yaml Configuration File
Add to your env.yaml file:
connections:
mysql_source:
type: mysql
host: localhost
port: 3306
user: username
password: mypassword
database: mydb
gcs_target:
type: gs
bucket: my-data-bucket
key_file: /path/to/service-account-key.json
Testing Connections
# Test MySQL connection
sling conns test mysql_source
# Test GCS connection
sling conns test gcs_target
# List all configured connections
sling conns list
For comprehensive connection configuration details, visit the Environment documentation.
Data Export with CLI Flags
Sling’s CLI provides a straightforward way to export data using command-line flags. This approach is perfect for one-off transfers or when you need quick results. The same flags apply when the target is another object store, such as exporting MySQL to S3 as Parquet or writing MySQL data to S3 in CSV, Parquet, and JSON.
Basic CLI Export Example
# Export a single MySQL table to GCS as CSV
sling run --src-conn mysql_source --src-stream users --tgt-conn gcs_target --tgt-stream users.csv
Advanced CLI Export Example
# Export with advanced source and target options
sling run \
--src-conn mysql_source \
--src-stream "SELECT id, name, email, created_at FROM users WHERE created_at >= '2024-01-01'" \
--src-options '{"limit": 10000}' \
--tgt-conn gcs_target \
--tgt-stream data/exports/users_export.csv \
--tgt-options '{"datetime_format": "2006-01-02T15:04:05Z07:00", "column_casing": "snake"}'
Format-Specific CLI Examples
Export to CSV
# Export MySQL table to GCS CSV with specific formatting
sling run \
--src-conn mysql_source \
--src-stream orders \
--tgt-conn gcs_target \
--tgt-stream exports/orders.csv \
--tgt-options '{"datetime_format": "2006-01-02T15:04:05Z07:00", "file_max_bytes": 104857600}'
Export to Parquet
# Export MySQL table to GCS Parquet for optimal compression and query performance
sling run \
--src-conn mysql_source \
--src-stream products \
--tgt-conn gcs_target \
--tgt-stream exports/products.parquet \
--tgt-options '{"column_casing": "lower", "file_max_bytes": 268435456}'
Export to JSON
# Export MySQL table to GCS JSON with proper formatting
sling run \
--src-conn mysql_source \
--src-stream customers \
--tgt-conn gcs_target \
--tgt-stream exports/customers.json \
--tgt-options '{"datetime_format": "2006-01-02T15:04:05Z07:00", "file_max_bytes": 52428800}'
For a complete overview of available CLI flags, visit the CLI Flags documentation.
Data Export with YAML Replications
For more complex scenarios involving multiple tables or recurring transfers, YAML replication files provide better organization and reusability. This approach is ideal for production environments and scheduled data pipelines.
Basic Replication Example
Create a file named mysql_to_gcs.yaml:
# Basic MySQL to GCS replication
source: mysql_source
target: gcs_target
streams:
users:
object: exports/users.csv
mode: full-refresh
target_options:
datetime_format: "2006-01-02T15:04:05Z07:00"
column_casing: snake
# Run the replication
sling run -r mysql_to_gcs.yaml
Advanced Multi-Stream Replication Example
Create a comprehensive replication file mysql_to_gcs_advanced.yaml:
# Advanced MySQL to GCS replication with multiple streams
source: mysql_source
target: gcs_target
# Default settings applied to all streams
defaults:
mode: full-refresh
target_options:
datetime_format: "2006-01-02T15:04:05Z07:00"
column_casing: snake
file_max_bytes: 104857600 # 100MB per file
streams:
# Export users table to CSV
users:
object: exports/csv/{stream_table}.csv
select:
- id
- name
- email
- created_at
- updated_at
where: "created_at >= '2024-01-01'"
# Export orders to Parquet for analytics
orders:
object: exports/parquet/{stream_table}.parquet
columns:
order_id: integer
customer_id: integer
order_date: datetime
total_amount: decimal
status: varchar
target_options:
file_max_bytes: 268435456 # 256MB for large dataset
# Export products with transformations to JSON
products:
object: exports/json/{stream_table}_{YYYY}_{MM}_{DD}.json
select:
- product_id
- name
- price
- category
- in_stock
source_options:
limit: 50000
# Export with runtime variables
customer_orders:
sql: "SELECT * FROM orders WHERE customer_id IN (SELECT id FROM customers WHERE region = 'US')"
object: exports/regional/{stream_file_name}_{YYYY}_{MM}_{DD}.parquet
# Run the advanced replication
sling run -r mysql_to_gcs_advanced.yaml
Format-Specific Replication Configurations
Multi-Table CSV Export
# Export multiple tables to CSV format
source: mysql_source
target: gcs_target
streams:
"public.*": # Wildcard to match all tables in public schema
object: csv_exports/{stream_table}.csv
mode: full-refresh
target_options:
datetime_format: "2006-01-02T15:04:05Z07:00"
column_casing: snake
Parquet with Column Transformations
# Export to Parquet with specific column handling
source: mysql_source
target: gcs_target
streams:
transactions:
object: parquet_exports/{stream_table}_{YYYY}_{MM}_{DD}.parquet
columns:
transaction_id: bigint
amount: decimal(10,2)
transaction_date: datetime
merchant_name: varchar(255)
target_options:
column_casing: lower
file_max_bytes: 536870912 # 512MB
JSON with Runtime Variables
# Export to JSON using runtime variables
source: mysql_source
target: gcs_target
streams:
daily_sales:
sql: "SELECT * FROM sales WHERE DATE(created_at) = CURDATE()"
object: json_exports/{stream_table}_{YYYY}_{MM}_{DD}_{HH}.json
target_options:
datetime_format: "2006-01-02T15:04:05Z07:00"
file_max_bytes: 104857600
For more details on replication concepts, visit the Replication documentation and Runtime Variables guide.
Advanced Configuration Options
Sling provides extensive configuration options to fine-tune your data exports for optimal performance and formatting.
MySQL Source Options
Table and Column Selection
streams:
users:
# Select specific columns
select:
- id
- username
- email
- created_at
# Filter data with WHERE clause
where: "status = 'active' AND created_at >= '2024-01-01'"
GCS Target Options
File Management
streams:
large_dataset:
object: exports/{stream_table}.parquet
target_options:
# Split large files (100MB each)
file_max_bytes: 104857600
# ISO 8601 datetime format
datetime_format: "2006-01-02T15:04:05Z07:00"
# Convert column names to snake_case
column_casing: snake
Advanced Formatting
streams:
formatted_export:
object: exports/formatted_{stream_table}.csv
target_options:
column_casing: lower
datetime_format: "2006-01-02T15:04:05Z07:00"
# Additional file-specific options
file_max_bytes: 52428800 # 50MB chunks
Runtime Variables Usage
Sling provides powerful runtime variables for dynamic file naming and organization:
streams:
daily_export:
object: exports/{stream_table}/{YYYY}/{MM}/{DD}/{stream_table}_{YYYY}_{MM}_{DD}_{HH}.parquet
timestamped_backup:
object: backups/{stream_file_name}_{YYYY}_{MM}_{DD}_{HH}.json
Available runtime variables:
{stream_table}: Source table name{stream_file_name}: Derived file name{YYYY},{MM},{DD}: Date components{HH},{mm},{ss}: Time components
For comprehensive source and target options, visit:
Sling Platform Overview
While the CLI is perfect for direct data operations, the Sling Platform provides a visual, collaborative environment for managing complex data workflows at scale.
Visual Workflow Creation
The Sling Platform offers an intuitive web interface where you can create, manage, and monitor your data pipelines visually.

Key platform features:
- Visual Editor: Drag-and-drop interface for creating data workflows
- Connection Management: Centralized connection configuration and testing
- Job Scheduling: Built-in scheduler for automated data transfers
- Execution History: Complete audit trail of all data operations
- Team Collaboration: Share workflows and manage access across teams
Connection Management in UI

The platform provides a user-friendly interface for managing all your connections:
- Connection Testing: Validate connections before use
- Credential Management: Secure storage of connection credentials
- Connection Sharing: Organize connections by team or project
Job Monitoring and Execution
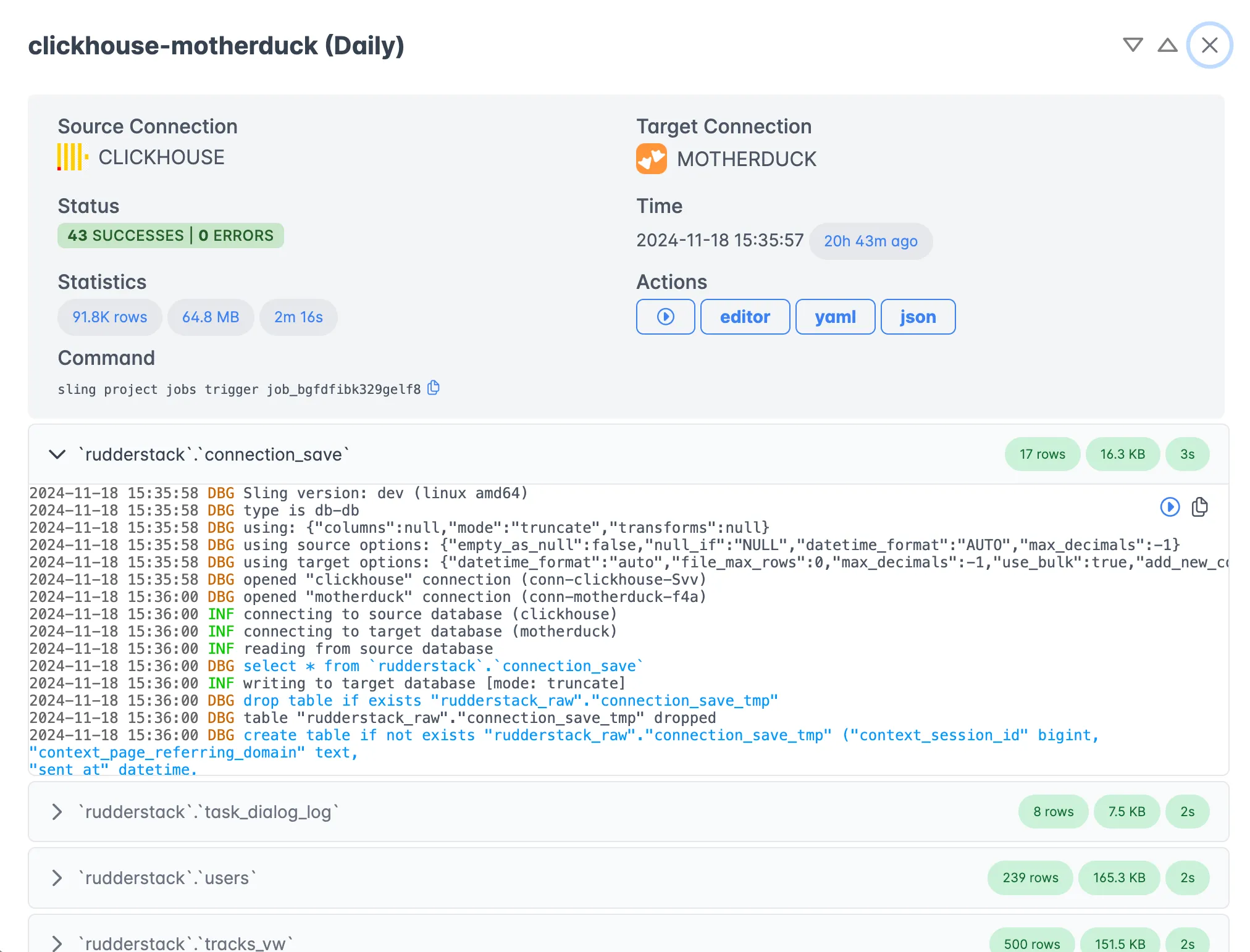
Monitor your data pipelines with comprehensive dashboards:
- Real-time Monitoring: Track job progress and performance metrics
- Execution History: View detailed logs and execution statistics
- Error Handling: Automatic alerts and retry mechanisms
- Performance Analytics: Optimize pipeline performance with detailed metrics
When to Use Platform vs CLI
Choose Sling CLI for:
- Development and testing
- One-off data transfers
- CI/CD integration
- Scripted automation
- Local development workflows
Choose Sling Platform for:
- Production data pipelines
- Team collaboration
- Visual workflow design
- Centralized monitoring
- Scheduled recurring jobs
To get started with the platform, visit Sling Platform Getting Started.
The Complete Sling Ecosystem
Sling provides a comprehensive ecosystem designed to handle data movement at any scale, from development to enterprise production environments.
Sling CLI Capabilities
The command-line interface serves as the foundation of the Sling ecosystem:
- Direct Execution: Run data transfers immediately from the command line
- Automation Ready: Perfect for CI/CD pipelines and scheduled scripts
- Development Friendly: Rapid prototyping and testing of data workflows
- Format Flexibility: Support for multiple data formats with built-in optimizations
Sling Platform Features
The web-based platform builds on the CLI foundation with enterprise features:
- Visual Workflow Builder: Create complex data pipelines through an intuitive interface
- Team Collaboration: Share connections, workflows, and monitor executions across teams
- Centralized Management: Unified view of all data operations and connections
- Advanced Scheduling: Cron-based scheduling with dependency management
- Monitoring & Alerting: Real-time monitoring with automated notifications
Sling Agents for Scalable Execution
Agents provide the distributed execution layer that makes Sling truly scalable:
- Your Infrastructure: Agents run in your environment, ensuring data never leaves your security boundary
- Auto-scaling: Dynamically scale execution based on workload demands
- High Availability: Built-in redundancy and failover mechanisms
- Resource Optimization: Intelligent resource allocation for optimal performance
Integration Capabilities
Sling integrates seamlessly with modern data stacks:
- Database Connections: MySQL, PostgreSQL, SQL Server, Oracle, MongoDB, and more
- Cloud Storage: AWS S3, Google Cloud Storage, Azure Blob Storage, and others
- Data Warehouses: Snowflake, BigQuery, Redshift, Databricks
- File Formats: CSV, Parquet, JSON, Avro, Delta Lake, and more
For detailed examples and use cases, explore:
Getting Started and Next Steps
Now that you understand Sling’s capabilities for MySQL to GCS data transfers, here’s how to take your next steps:
Quick Start Recommendations
- Start with CLI: Install Sling CLI and test basic transfers
- Configure Connections: Set up your MySQL and GCS connections using the method that works best for your environment
- Test Small Transfers: Start with a small table to validate your setup
- Scale Up: Move to YAML replications for production workflows
- Explore Platform: Try the visual interface for team collaboration
Additional Documentation
Dive deeper into specific topics:
- Replication Modes: Learn about incremental, full-refresh, and other modes
- Connection Types: Explore all database and storage connections
- Advanced Features: Master transforms and data quality features
Community Resources and Support
Join the Sling community:
- Documentation: Comprehensive guides at docs.slingdata.io
- Discord Community: Get help and share experiences on Discord
- GitHub: Report issues and contribute at github.com/slingdata-io
- Support: Direct support at [email protected]
Advanced Use Cases
Once you’re comfortable with basic transfers, explore advanced scenarios:
- Incremental Synchronization: Keep your GCS data in sync with MySQL changes
- Data Transformations: Apply transformations during the transfer process
- Parallel Processing: Handle large datasets with parallel chunking
- Scheduled Pipelines: Automate regular data exports
- Multi-Format Exports: Export the same data to multiple formats simultaneously
If your roadmap also includes warehouse or database targets, see loading MySQL into Snowflake and syncing MySQL to Postgres. For a similar object-store flow from Postgres, see exporting Postgres to S3 as Parquet.
Frequently Asked Questions
What file formats can Sling export from MySQL to Google Cloud Storage?
Sling exports to CSV, Parquet, and JSON, among other formats. The format is chosen by the target object’s file extension, so naming the object users.parquet produces Parquet and users.csv produces CSV.
How do I authenticate Sling to Google Cloud Storage?
Create a Google Cloud service account, grant it the Storage Object Admin role on the bucket, download the JSON key, and point the connection’s key_file at that file. You configure it once with sling conns set or in your env.yaml and Sling uses it for every run.
Can Sling split large MySQL exports into multiple files on GCS?
Yes. Set file_max_bytes in target_options to a byte threshold and Sling writes a new file each time the current one reaches that size. This keeps individual objects small enough for parallel reads by downstream tools.
How do I export only specific rows or columns from a MySQL table?
Use select to choose columns and a SQL query as the source stream to filter rows, or pass a custom sql in the stream. Sling reads only the data you ask for and writes just that to Google Cloud Storage.
Can I export multiple MySQL tables to GCS in one run?
Yes. List each table under streams in a YAML replication, or use a wildcard like public.* to match every table in a schema. A single sling run command writes all of them to the bucket using the shared defaults block.
Is Parquet or CSV better for exporting MySQL data to GCS?
Parquet is usually the better choice for analytics because it is columnar, compresses well, and is read efficiently by BigQuery, Spark, and DuckDB. CSV is more portable and human-readable, so it is a good fit when a downstream system expects plain text or when you need to inspect the data directly.
Does Sling support date-partitioned file paths on GCS?
Yes. Use runtime variables such as {YYYY}, {MM}, and {DD} in the object path and Sling substitutes the current date at run time. This lets you write objects into a date-based folder layout like exports/2026/06/11/ automatically.
Conclusion
Traditional data pipelines for exporting MySQL data to Google Cloud Storage often involve complex infrastructure, custom code, and ongoing maintenance overhead. Sling transforms this process into a simple, reliable, and scalable solution.
With Sling, you can:
- Export data in minutes instead of weeks of development
- Use simple CLI commands or visual workflows instead of complex ETL code
- Support multiple formats (CSV, Parquet, JSON) with optimized performance
- Scale from development to enterprise with the same consistent tooling
- Collaborate effectively with team-friendly platform features
Whether you’re a data engineer building production pipelines, an analyst needing occasional exports, or a developer prototyping data workflows, Sling provides the right tool for your MySQL to GCS data movement needs.
Start your journey today with the Sling CLI installation, or explore the Sling Platform for a managed experience.
The future of data movement is simple, fast, and reliable. The future is Sling.