
Last updated: May 2026
Introduction
In today’s data-driven world, efficiently moving data between databases is crucial for businesses. Whether you’re synchronizing data across environments or migrating to a new system, having the right tools can make all the difference. Enter Sling, a modern data movement and transformation platform designed to simplify these tasks.
What is Sling?
Sling is a powerful tool that streamlines data operations by providing both a command-line interface (CLI) and a comprehensive platform for managing data workflows. It supports a wide range of databases and storage systems, making it a versatile choice for data engineers and developers.
You can use Sling in two ways:
- Sling CLI: Perfect for local development, testing, and CI/CD pipelines
- Sling Platform: A web-based interface for visual workflow creation, team collaboration, and production deployments
Why Use Sling for PostgreSQL Data Transfers?
When it comes to moving data between PostgreSQL databases, Sling offers several advantages:
- Efficiency: Sling is optimized for fast and reliable data transfers, minimizing downtime and ensuring data integrity.
- Flexibility: With support for various replication modes, including full-refresh and incremental updates, Sling adapts to your specific needs.
- Transformation Capabilities: Built-in data transformation features allow you to modify data on-the-fly during transfers.
- Production-Ready: Sling is designed for production environments, offering features like monitoring, scheduling, and error handling.
Use Case: Postgres-to-Postgres Data Movement
Imagine you need to replicate data from a production PostgreSQL database to a staging environment for testing. Sling makes this process straightforward, allowing you to focus on your core tasks without worrying about data consistency or transfer errors.
If you need to send the same data to a warehouse instead, Sling supports the same pattern for Postgres to Snowflake and Postgres to BigQuery.
Prerequisites
Before you get started with Sling, ensure you have the following:
- PostgreSQL Instances: Two PostgreSQL databases (source and target) that you want to synchronize.
- Access Credentials: Valid credentials with the necessary permissions to read from the source and write to the target database.
- Basic Command-Line Knowledge: Familiarity with using the command line will help you navigate Sling’s CLI efficiently.
With these prerequisites in place, you’re ready to harness the power of Sling for your PostgreSQL data transfers. In the following sections, we’ll guide you through the installation, configuration, and execution of Sling to achieve seamless data movement between your databases.
Installing Sling CLI
Before diving into PostgreSQL data transfers, let’s get Sling installed on your system. Sling offers several installation methods depending on your operating system, making it easy to get started quickly.
Mac Installation
If you’re on macOS, the easiest way to install Sling is through Homebrew:
brew install slingdata-io/sling/sling
Windows Installation
Windows users can install Sling using the Scoop package manager. If you don’t have Scoop installed yet, you can get it from scoop.sh. Here’s how to install Sling:
# Add the Sling bucket to Scoop
scoop bucket add sling https://github.com/slingdata-io/scoop-sling.git
# Install Sling
scoop install sling
Linux Installation
For Linux systems, you can download and install Sling directly using curl:
curl -LO 'https://github.com/slingdata-io/sling-cli/releases/latest/download/sling_linux_amd64.tar.gz' \
&& tar xf sling_linux_amd64.tar.gz \
&& rm -f sling_linux_amd64.tar.gz \
&& chmod +x sling
# Move to a directory in your PATH (optional)
sudo mv sling /usr/local/bin/
Docker Installation
If you prefer using Docker, Sling provides an official Docker image:
docker pull slingdata/sling
# Test the installation
docker run --rm -i slingdata/sling --help
Verifying Your Installation
After installing Sling, it’s important to verify that everything is working correctly. Run these basic commands to check your installation:
# Check Sling version
sling --version
# View available commands
sling --help
# List any configured connections
sling conns list
Setting Up Database Connections in Sling
Before we can move data between PostgreSQL databases, we need to configure our source and target connections. You can manage connections either through the CLI or the Sling Platform UI.
Using the Sling Platform (Recommended for Teams)
The Sling Platform provides a visual interface for managing connections securely:
Benefits of using the Platform include:
- Centralized credential management
- Team access controls
- Connection health monitoring
- Easy testing and validation
Using the CLI (Great for Local Development)
Sling CLI offers two ways to configure database connections:
- Direct CLI commands (great for quick testing)
- Environment file (recommended for production use)
Let’s explore both methods.
Method 1: Using CLI Commands
For quick setup and testing, you can configure connections directly through the CLI. Here’s how to set up your source PostgreSQL connection:
sling conns set SOURCE_PG \
type=postgres \
host=source-db.example.com \
port=5432 \
database=analytics \
username=reader \
password=your_password
And similarly for your target database:
sling conns set TARGET_PG \
type=postgres \
host=target-db.example.com \
port=5432 \
database=warehouse \
username=writer \
password=your_password
Method 2: Using env.yaml (Recommended)
For production environments, it’s better to store your connection details in an env.yaml file. This approach offers better security and version control capabilities.
Create an env.yaml file in your project directory:
connections:
SOURCE_PG:
type: postgres
host: source-db.example.com
port: 5432
database: analytics
username: reader
password: your_password
TARGET_PG:
type: postgres
host: target-db.example.com
port: 5432
database: warehouse
username: writer
password: your_password
Method 3: Using Environment Variables
If you prefer using environment variables, especially in CI/CD environments:
# For Linux/Mac
export SOURCE_PG='postgresql://sling:[email protected]:5432/source_db'
export TARGET_PG='postgresql://sling:[email protected]:5432/target_db'
# For Windows PowerShell
$env:SOURCE_PG='postgresql://sling:[email protected]:5432/source_db'
$env:TARGET_PG='postgresql://sling:[email protected]:5432/target_db'
Testing Your Connections
Always verify your connections before running replications. Use the test command:
# Test source connection
sling conns test SOURCE_PG
# Test target connection
sling conns test TARGET_PG
Creating a Replication Configuration in Sling
Moving data between PostgreSQL databases becomes much simpler when you understand how to create effective replication configurations in Sling. Let’s explore how to set this up, starting with basic examples and moving to more advanced scenarios.
Basic Single-Table Replication
The simplest way to start is by replicating a single table. Here’s a basic configuration that copies data from one table to another:
source: SOURCE_PG
target: TARGET_PG
streams:
source_schema.customers:
object: target_schema.customers
mode: full-refresh
This configuration will:
- Connect to your source PostgreSQL database
- Copy all data from
source_schema.customers - Create or replace
target_schema.customersin your target database
Using Default Settings
When you’re working with multiple tables that share common settings, you can use the defaults section to avoid repetition:
source: SOURCE_PG
target: TARGET_PG
defaults:
mode: full-refresh
object: '{target_schema}.{stream_table}'
streams:
source_schema.customers:
source_schema.orders:
source_schema.products:
Pro tip: Using defaults makes your configuration more maintainable and less prone to errors.
Replicating Multiple Tables with Wildcards
One of Sling’s most powerful features is the ability to replicate multiple tables using wildcards. Here’s how to replicate an entire schema:
source: SOURCE_PG
target: TARGET_PG
defaults:
mode: full-refresh
object: 'analytics.{stream_schema}_{stream_table}'
streams:
sales.*: # This will replicate all tables in the 'sales' schema
You can also exclude specific tables while using wildcards:
streams:
sales.*: # Replicate all tables in sales schema
sales.temp_calculations:
disabled: true # This table will be skipped
sales.archived_orders:
disabled: true # This table will also be skipped
Using Runtime Variables
Runtime variables make your configurations dynamic and flexible. Here are some useful variables you can use:
{stream_schema}: Source table’s schema name{stream_table}: Source table’s name{target_schema}: Target database’s default schema{run_timestamp}: Current timestamp (format: YYYY_MM_DD_HHMMSS)
Here’s a practical example:
source: SOURCE_PG
target: TARGET_PG
defaults:
mode: full-refresh
object: '{target_schema}.{stream_schema}_{stream_table}_{YYYY}_{MM}'
streams:
analytics.daily_metrics:
analytics.user_activity:
tags: [critical]
This configuration will create tables with names like target_schema.analytics_daily_metrics_2024_01.
Advanced Configuration Examples
Incremental Updates
For tables that are frequently updated, use incremental mode:
streams:
transactions.orders:
mode: incremental
object: prod.orders
primary_key: [order_id]
update_key: last_modified_at
Custom SQL Queries
Sometimes you need more control over the source data:
streams:
custom_orders:
sql: |
SELECT
o.order_id,
c.customer_name,
o.order_date,
o.total_amount
FROM sales.orders o
JOIN sales.customers c ON o.customer_id = c.id
WHERE o.order_date >= current_date - interval '7 days'
object: analytics.recent_orders
Running Your Replication
There are two main ways to execute replications with Sling: using a configuration file or direct CLI commands. Let’s explore both approaches.
Using a Configuration File
If you’ve created a replication YAML file (as discussed in previous sections), running it is straightforward:
sling run -r replication.yaml
This command will process all enabled streams in your configuration file. You can also run specific streams by using tags:
# Run only streams tagged with 'critical'
sling run -r replication.yaml --stream tags:critical
Quick Ad-hoc Transfers
For one-off transfers or testing, you can use direct CLI commands without creating a configuration file:
sling run \
--src-conn SOURCE_PG \
--src-stream "public.customers" \
--tgt-conn TARGET_PG \
--tgt-object "new_schema.customers_backup" \
--mode full-refresh
Production Deployments with Sling Platform
While the CLI is great for development and testing, the Sling Platform offers additional features for production environments:
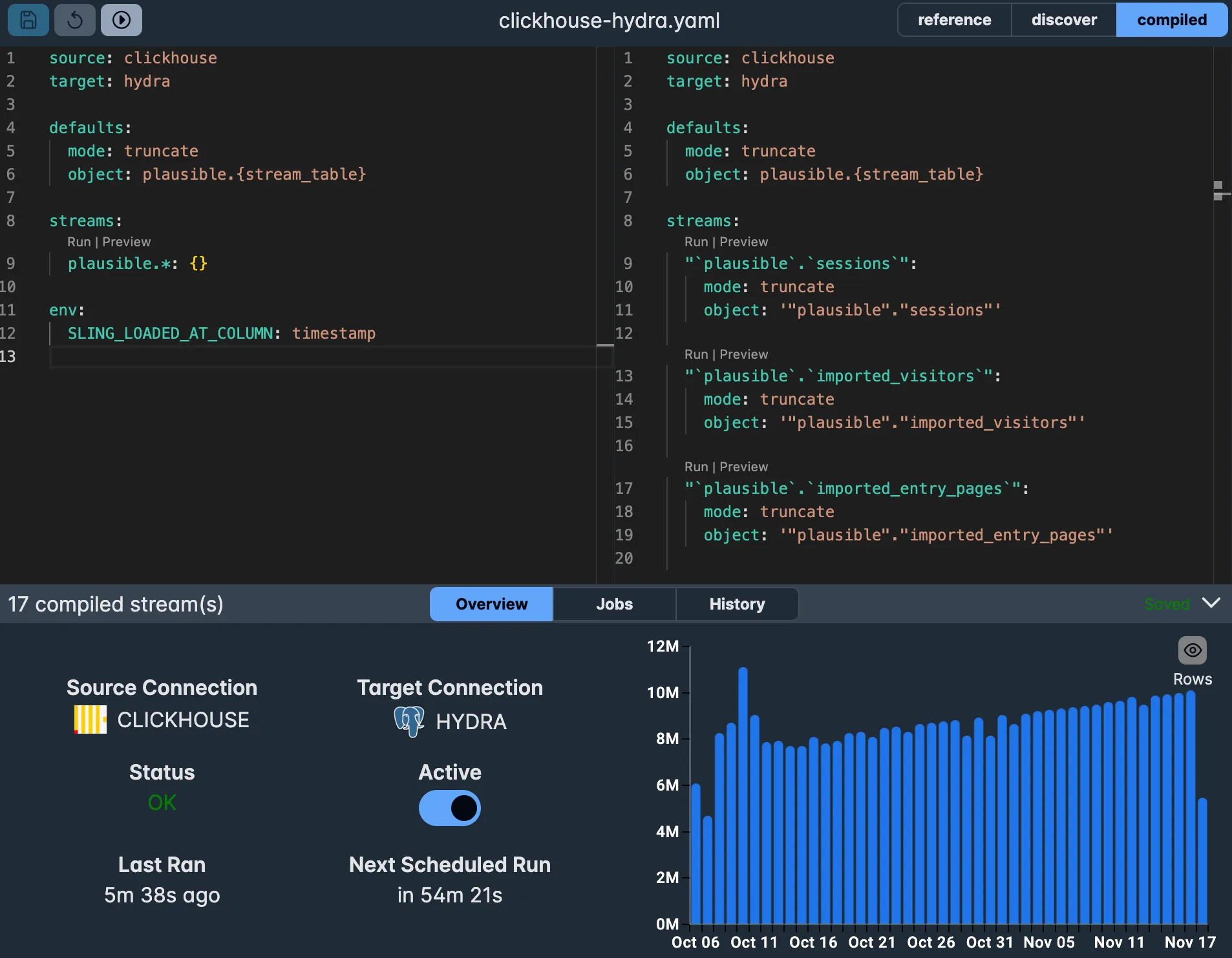
Key benefits include:
- Visual replication builder
- Job scheduling and monitoring
- Team collaboration features
- Error alerting and notifications
You can learn more about the Sling Platform at docs.slingdata.io.
Advanced Features for PostgreSQL Data Movement with Sling
Moving data between PostgreSQL databases isn’t always as simple as copying entire tables. In this section, I’ll show you some powerful advanced features that make Sling an incredibly flexible tool for your data movement needs.
Incremental Updates
One of the most common requirements in data movement is keeping your target database up-to-date with only the latest changes. Sling makes this easy with its incremental mode.
Here’s a simple configuration that tracks changes using a last_modified timestamp:
source: SOURCE_PG
target: TARGET_PG
streams:
sales.orders:
mode: incremental
update_key: last_modified
primary_key: [order_id]
object: analytics.orders_current
This configuration will:
- Only fetch records newer than the last sync
- Update existing records if they’ve changed
- Insert new records that don’t exist in the target
- Use
order_idfor matching records during updates
Smart SQL Transformations
Sometimes you need to transform or filter your data during transfer. Instead of creating views in your source database, you can use custom SQL queries directly in your Sling configuration:
streams:
active_customers.custom:
sql: |
SELECT
customer_id,
first_name,
last_name,
email,
created_at,
last_modified
FROM customers.users
WHERE status = 'active'
AND deleted_at IS NULL
object: analytics.active_customers
mode: incremental
update_key: last_modified
primary_key: [customer_id]
Pro tip: When using incremental mode with custom SQL, include the special placeholder
{incremental_where_cond}in your query to let Sling handle the incremental logic:
streams:
recent_orders.custom:
sql: |
SELECT * FROM sales.orders
WHERE {incremental_where_cond}
AND status != 'cancelled'
object: analytics.recent_orders
mode: incremental
update_key: updated_at
primary_key: [order_id]
Column Transformations
Sling provides several built-in transformations that you can apply to your data during transfer. Here’s how to use them:
streams:
customers.users:
object: analytics.cleaned_users
transforms:
# Apply to specific columns
email: [trim_space, decode_utf8]
name: [replace_non_printable, trim_space]
# Apply to all columns
"*": [decode_latin1]
Available transformations include:
trim_space: Remove leading/trailing whitespacereplace_non_printable: Clean up invisible charactersdecode_utf8: Fix encoding issuesreplace_accents: Normalize accented characters- And many more!
Advanced Loading Strategies
Sling offers different loading modes for various scenarios:
streams:
# Snapshot mode: Keep historical versions
finance.transactions:
mode: snapshot
object: finance.transactions_history
# Truncate mode: Preserve table structure
config.settings:
mode: truncate
object: app.settings
# Backfill mode: Load specific date ranges
orders.historical:
mode: backfill
update_key: order_date
source_options:
range: "2023-01-01,2023-12-31"
object: analytics.orders_2023
Conclusion
Moving data between PostgreSQL databases doesn’t have to be complicated. With Sling, you can establish reliable, efficient data pipelines in minutes rather than hours. Whether you’re performing one-time migrations or setting up ongoing synchronization, Sling’s flexible configuration options and robust feature set make it an excellent choice for database-to-database operations.
For more information about Sling and its capabilities, visit the official documentation or join our community on Discord.
Related Guides
- Postgres to ClickHouse — when the read pattern is analytical rather than transactional
- Postgres to DuckDB — for local analytical extracts
- Sync MySQL to Postgres — same incremental patterns, different source
Frequently Asked Questions
What’s the difference between full-refresh and incremental mode for Postgres-to-Postgres replication?
full-refresh truncates the target and reloads the entire source table on every run — simple, but expensive on large tables. incremental requires a primary_key and update_key (such as updated_at) and only moves rows newer than the last sync, so it’s the right default for tables that change frequently.
Can Sling replicate the schema and indexes, or only the data?
Sling creates the target table with appropriate column types if it doesn’t exist, but it does not copy indexes, foreign keys, triggers, sequences, or stored procedures. For schema-faithful migrations, run pg_dump --schema-only against the source first, apply it on the target, then use Sling to load the rows.
How do I avoid moving sensitive columns to a staging or lower environment?
Use select to drop columns by name — for example select: ["-password_hash", "-ssn"] — or use the sql: field with an explicit column list. Sling also supports column-level transforms like hashing if you want to anonymize rather than remove the data.
Does Sling support snapshotting historical states of a table?
Yes. mode: snapshot writes each run as a versioned slice into the target, typically suffixed with a timestamp using runtime variables like {run_timestamp}. This is useful for slowly changing dimensions or audit trails where you want to retain prior versions.
Can I move data between Postgres instances with different versions or extensions?
Yes — Sling reads through the standard wire protocol, so version differences are not a problem. Extension-specific column types (postgis geometries, hstore, custom enums) are mapped to a compatible base type by default; if you need exact preservation, install the same extensions on the target before replicating.
How do I limit the load Sling puts on the source database?
Run during off-peak hours, replicate from a read replica when possible, and use incremental mode with an indexed update_key so the source query is a fast range scan rather than a full table scan. You can also tune source_options.limit for testing or staged backfills.
Can the same replication YAML run from CI/CD or a Sling Platform schedule?
Yes — the YAML file is portable. From CI/CD you invoke sling run -r replication.yaml after exporting connection env vars; on the Sling Platform you commit the same file and attach a schedule, with logging and alerting handled for you.