
Last updated: June 2026
Moving data between PostgreSQL and ClickHouse can be a complex endeavor, often requiring significant engineering effort to build and maintain reliable data pipelines. Traditional approaches involve writing custom ETL scripts, managing data type conversions, handling schema changes, and ensuring data consistency—all while maintaining real-time synchronization between these two powerful but very different database systems.
In this comprehensive guide, we’ll explore how Sling simplifies the process of replicating data from PostgreSQL to ClickHouse, enabling you to harness PostgreSQL’s robust transactional capabilities alongside ClickHouse’s exceptional analytical performance. We’ll walk through the entire setup process, from establishing connections to configuring real-time replication, and demonstrate how Sling’s features make this integration seamless and efficient.
Getting Started with Sling
Before we dive into the specifics of PostgreSQL to ClickHouse replication, let’s set up Sling on your system. Sling offers multiple installation methods to suit your environment:
# macOS / Linux
curl -fsSL https://slingdata.io/install.sh | bash
# Windows
irm https://slingdata.io/install.ps1 | iex
# Python
pip install sling
After installation, verify that Sling is properly installed:
# Check Sling version
sling --version
For more detailed installation instructions, visit the Sling CLI Getting Started Guide.
Setting Up Database Connections
To begin replicating data, we need to configure connections for both PostgreSQL and ClickHouse. Let’s set up each connection using Sling’s flexible configuration options.
PostgreSQL Connection Setup
You’ll need the following information for your PostgreSQL connection:
- Host address
- Port number (default: 5432)
- Database name
- Username
- Password
- SSL mode (if required)
Here are three ways to configure your PostgreSQL connection:
Using Environment Variables
# Set PostgreSQL connection using environment variable
export PG_SOURCE='postgresql://user:pass@host:5432/dbname?sslmode=require'
Using the Sling CLI
# Set up PostgreSQL connection with individual parameters
sling conns set pg_source type=postgres host=host.ip user=myuser database=mydatabase password=mypass port=5432
# Or use a connection URL
sling conns set pg_source url="postgresql://user:pass@host:5432/dbname?sslmode=require"
Using the Sling Environment File
Add to your ~/.sling/env.yaml:
connections:
pg_source:
type: postgres
host: host.ip
user: myuser
password: mypass
port: 5432
database: mydatabase
sslmode: require
schema: public
ClickHouse Connection Setup
For ClickHouse, you’ll need:
- Host address
- Port number (default: 9000)
- Database name
- Username (if required)
- Password (if required)
Configure your ClickHouse connection using any of these methods:
Using Environment Variables
# Set ClickHouse connection using environment variable
export CH_TARGET='clickhouse://user:pass@host:9000/dbname'
Using the Sling CLI
# Set up ClickHouse connection with individual parameters
sling conns set ch_target type=clickhouse host=host.ip user=myuser database=mydatabase password=mypass port=9000
# Or use a connection URL
sling conns set ch_target url="clickhouse://user:pass@host:9000/dbname"
Using the Sling Environment File
Add to your ~/.sling/env.yaml:
connections:
ch_target:
type: clickhouse
host: host.ip
user: myuser
password: mypass
port: 9000
database: mydatabase
Testing Your Connections
After setting up both connections, verify they’re working correctly:
# Test PostgreSQL connection
sling conns test pg_source
# Test ClickHouse connection
sling conns test ch_target
# List available tables in PostgreSQL
sling conns discover pg_source
For more details about connection configuration, visit:
Understanding PostgreSQL and ClickHouse Integration
PostgreSQL and ClickHouse serve different but complementary purposes in modern data architectures. PostgreSQL excels as a transactional database with strong ACID compliance, making it ideal for operational workloads. ClickHouse, on the other hand, is designed for high-performance analytical queries on large datasets, with impressive columnar storage and parallel processing capabilities.
Combining these databases creates a powerful system where:
- PostgreSQL handles transactional data and OLTP workloads
- ClickHouse provides rapid analytics and OLAP capabilities
- Real-time replication ensures analytics are based on current data
However, setting up this integration traditionally requires:
- Writing custom data extraction scripts
- Managing data type mappings between systems
- Implementing change data capture (CDC)
- Handling schema evolution
- Setting up monitoring and error handling
- Maintaining infrastructure for the pipeline
Sling eliminates these complexities by providing:
- Built-in support for both PostgreSQL and ClickHouse
- Automatic schema mapping and evolution
- Efficient change data capture
- Real-time replication with minimal latency
- Simple configuration through CLI or YAML
- Comprehensive monitoring and error handling
Basic Data Replication
With our connections set up, let’s explore how to replicate data from PostgreSQL to ClickHouse using Sling’s CLI. We’ll start with simple examples and gradually move to more complex configurations.
Simple CLI Replication
The most basic way to replicate data is using Sling’s CLI flags. Here’s a simple example:
# Replicate a single table with default options
sling run --src-conn pg_source --tgt-conn ch_target --src-stream users --tgt-object default.orders
This command will:
- Read the
userstable from PostgreSQL - Automatically create the table in ClickHouse if it doesn’t exist
- Copy all data using the default full-refresh mode
- Maintain column types and names
Here’s a more advanced example with additional options:
# Replicate with specific options and column selection
sling run \
--src-conn pg_source \
--tgt-conn ch_target \
--src-stream orders \
--tgt-object default.orders \
--mode incremental \
--select "id, customer_id, order_date, total_amount, status" \
--tgt-options '{ "column_casing": "snake", "add_new_columns": true }'
This command demonstrates:
- Incremental replication mode
- Column selection
- Target options for column casing and schema evolution
For more details about CLI flags and options, visit the CLI Flags Documentation.
Advanced Replication Configuration
For more complex replication scenarios, Sling supports YAML configuration files. This approach provides better version control, reusability, and more advanced features.
Basic YAML Configuration
Create a file named postgres_to_clickhouse.yaml:
# Define source and target connections
source: pg_source
target: ch_target
# Default settings for all streams
defaults:
mode: incremental
target_options:
# Automatically add new columns if they appear in source
add_new_columns: true
# Convert column names to snake_case
column_casing: snake
# Use ClickHouse's native types
table_ddl: |
engine = MergeTree()
order by (id)
partition by toYYYYMM(created_at)
# Define the tables to replicate
streams:
# Users table replication
users:
# Use runtime variable for target table name
object: analytics.{stream_table}
# Specify primary key for incremental updates
primary_key: [id]
# Track updates using timestamp column
update_key: updated_at
# Select specific columns
select: [
"id",
"email",
"full_name",
"created_at",
"updated_at",
"status"
]
# Orders table replication
orders:
object: analytics.{stream_table}
primary_key: [order_id]
update_key: modified_at
# Custom SQL query for source data
sql: |
SELECT
o.order_id,
o.customer_id,
o.order_date,
o.total_amount,
o.status,
c.email as customer_email
FROM orders o
JOIN customers c ON o.customer_id = c.id
WHERE o.order_date >= '2024-01-01'
To run this replication:
# Run the replication using the YAML config
sling run -r postgres_to_clickhouse.yaml
Complex YAML Configuration
Here’s a more advanced configuration that demonstrates additional features:
source: pg_source
target: ch_target
defaults:
mode: incremental
target_options:
add_new_columns: true
column_casing: snake
table_ddl: create table {object_name} ({col_types}) engine = MergeTree
# Add hooks for pre and post processing
hooks:
pre:
- type: query
conn: ch_target
sql: "OPTIMIZE TABLE {target_schema}.{target_table} FINAL"
post:
- type: http
url: "https://api.example.com/webhook"
method: POST
headers:
Content-Type: application/json
body: |
{
"event": "replication_complete",
"stream": "{stream_name}",
"rows": {rows_written}
}
streams:
# Customer transactions
transactions:
object: analytics.{stream_table}
primary_key: [transaction_id]
update_key: modified_at
# Transform columns during replication
transforms:
amount: ["trim"]
status: ["upper"]
# Target-specific options
target_options:
table_keys:
primary: ["transaction_id"]
unique: ["order_id", "customer_id"]
# Customer analytics
customer_metrics:
object: analytics.customer_metrics
sql: |
WITH customer_stats AS (
SELECT
customer_id,
COUNT(DISTINCT order_id) as total_orders,
SUM(amount) as total_spent,
MAX(transaction_date) as last_transaction_date
FROM transactions
GROUP BY customer_id
)
SELECT
c.*,
cs.total_orders,
cs.total_spent,
cs.last_transaction_date,
CASE
WHEN cs.total_spent >= 1000 THEN 'VIP'
WHEN cs.total_spent >= 500 THEN 'Regular'
ELSE 'New'
END as customer_segment
FROM customers c
LEFT JOIN customer_stats cs ON c.id = cs.customer_id
This configuration showcases:
- Custom table engines for ClickHouse
- Pre and post-processing hooks
- Column transformations
- Complex SQL queries
- Table keys and constraints
- Runtime variables
For more information about replication configuration, visit:
Sling Platform Components
While the CLI is powerful for local development and simple deployments, the Sling Platform provides a comprehensive web-based interface for managing and monitoring your data replications at scale.
Platform Overview
The Sling Platform consists of several key components:
- Web Interface: A modern UI for managing connections, creating replications, and monitoring jobs
- Agents: Distributed workers that execute replications in your infrastructure
- Control Plane: Centralized management and orchestration
- Monitoring: Real-time visibility into replication status and performance
Getting Started with the Platform
To use the Sling Platform:
- Sign up at app.slingdata.io
- Deploy a Sling Agent in your infrastructure
- Configure your connections through the UI
- Create and manage replications visually
Visual Replication Management
The platform provides an intuitive interface for:
- Managing database connections
- Creating and editing replication configurations
- Monitoring replication status and performance
- Setting up schedules and triggers
- Configuring alerts and notifications

Connection Management
The platform simplifies connection management with a visual interface:
- Click “Add Connection” to create a new connection
- Select the connection type (PostgreSQL or ClickHouse)
- Fill in the connection details
- Test the connection directly from the UI

Monitoring and History
The platform provides comprehensive monitoring capabilities:
- Real-time execution monitoring
- Historical job performance
- Detailed logs and error reporting
- Success/failure notifications
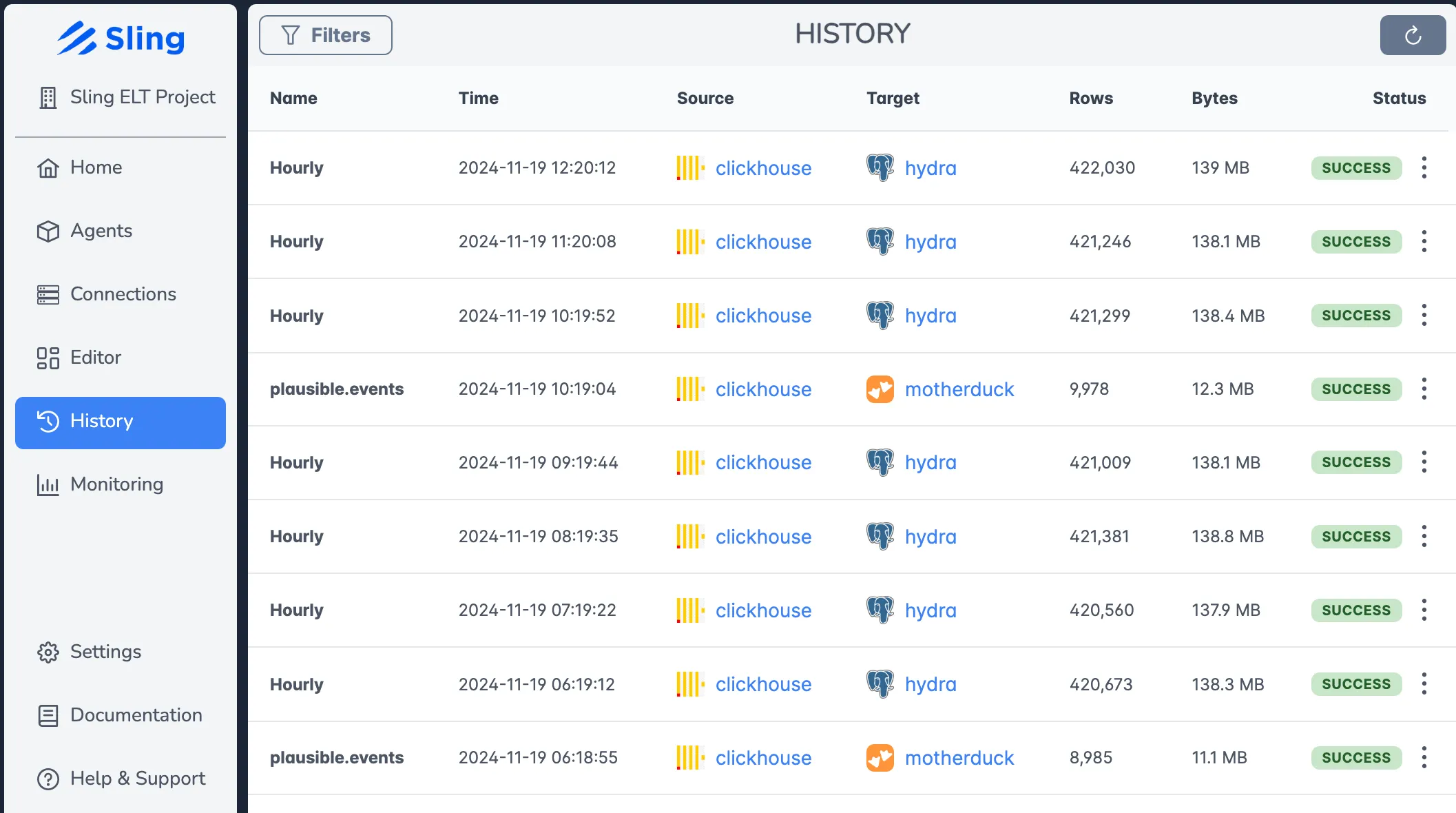
For more information about the Sling Platform, visit:
Best Practices and Next Steps
To ensure successful PostgreSQL to ClickHouse replication with Sling, consider these best practices:
Performance Optimization
- Use Incremental Mode: For large tables, use incremental mode with appropriate update keys
- Optimize Batch Sizes: Adjust batch limits based on your data volume and system resources
- Choose Appropriate ClickHouse Engines: Select the right table engine for your use case
- Partition Strategy: Implement effective partitioning in ClickHouse for better query performance
Production Deployment
- Monitor Resource Usage: Keep an eye on CPU, memory, and network usage
- Set Up Alerts: Configure notifications for replication failures or delays
- Regular Maintenance: Schedule routine maintenance tasks like OPTIMIZE operations
- Version Control: Keep your replication configurations in version control
- Security: Use secure connection methods and follow least privilege principles
Next Steps
To continue your journey with Sling:
- Explore the documentation for detailed features and options
- Join the Sling community on Discord for support and discussions
- Check out example configurations in the documentation
- Consider upgrading to the Sling Platform for enterprise features
Remember that Sling is actively developed, with new features and improvements regularly added. Stay updated with the latest releases to take advantage of new capabilities and optimizations.
Related Guides
The same replication file shape works for other PostgreSQL targets. If you want a DuckDB analytics layer instead of ClickHouse, see PostgreSQL to DuckDB or the serverless PostgreSQL to MotherDuck guide. To land flat files rather than warehouse tables, PostgreSQL to S3 as Parquet covers a file-system target. For a Snowflake destination, see PostgreSQL to Snowflake.
FAQ
Does Sling support change data capture (CDC) from PostgreSQL to ClickHouse?
Sling uses key-based incremental replication rather than log-based CDC. You set an update_key (such as updated_at) and a primary_key, and Sling reads only rows newer than the last checkpoint on each run, then upserts them by primary key.
Which ClickHouse table engine does Sling use when it creates a target table?
By default Sling creates a MergeTree table. You can override the DDL with the table_ddl target option to set a specific engine, ORDER BY clause, or partition expression that fits your query patterns.
How does Sling handle PostgreSQL data types that ClickHouse does not have?
Sling maps source types to the closest ClickHouse equivalent automatically during table creation. For full control you can declare explicit column types in the stream’s columns block so the target schema matches what your queries expect.
Can I replicate only a subset of columns from a PostgreSQL table?
Yes. Use the select option in a stream (or the --select CLI flag) to list the columns to copy, or prefix a column with a minus sign to exclude it. You can also use a custom sql block to project and filter rows at the source.
Why are temporary tables appearing in ClickHouse during replication?
Sling loads data into a staging table first, then swaps it into the final target table once the load succeeds. These _tmp tables are part of normal operation and are cleaned up automatically when the stream finishes.
How do I schedule PostgreSQL to ClickHouse replication to run on a recurring basis?
With the CLI you can wrap the sling run command in cron or any scheduler. The Sling Platform adds built-in scheduling, run history, and alerting on top of the same replication file.
Does incremental mode update existing rows or only insert new ones?
If you set a primary_key, incremental mode upserts: new rows are inserted and changed rows replace the existing ones. With only an update_key and no primary key, Sling appends new rows without deduplicating.