
Introduction
In today’s data-driven world, moving data from PostgreSQL databases to Amazon S3 as CSV files is a common requirement for data analytics, backup, and integration purposes. However, setting up this data pipeline traditionally involves complex scripts, managing dependencies, and handling various edge cases. Sling simplifies this process by providing an intuitive platform for data movement and transformation, eliminating the typical complexities of database exports. This guide will walk you through using Sling to streamline your PostgreSQL to S3 CSV exports, covering installation, configuration, and best practices.
Understanding Traditional Data Pipeline Challenges
Setting up a data pipeline to export data from PostgreSQL to S3 CSV files traditionally involves several challenges:
Complex Setup Process
The conventional approach often requires:
- Writing custom Python scripts using libraries like psycopg2 and boto3
- Managing database connections and AWS credentials
- Handling large datasets with memory constraints
- Implementing error handling and retries
- Setting up proper file naming and organization in S3
Resource Intensive
Traditional methods can be resource-intensive in terms of:
- Development time for writing and testing scripts
- System resources when handling large data exports
- Ongoing maintenance of custom solutions
- Documentation and knowledge transfer
- Managing dependencies and library versions
Common Limitations
Standard approaches often face limitations such as:
- Lack of incremental update support
- Limited data type handling capabilities
- No built-in scheduling or monitoring
- Difficulty in handling schema changes
- Complex error recovery processes
These challenges make what should be a simple task into a complex undertaking. This is where Sling comes in, offering a streamlined solution that addresses these pain points with its modern approach to data movement.
Getting Started with Sling
Before we dive into exporting data from PostgreSQL to S3, let’s set up Sling on your system. Sling offers multiple installation methods to suit different operating systems and preferences.
Installation
Choose the installation method that matches your operating system:
# Install using Homebrew (macOS)
brew install slingdata-io/sling/sling
# Install using curl (Linux)
curl -LO 'https://github.com/slingdata-io/sling-cli/releases/latest/download/sling_linux_amd64.tar.gz' \
&& tar xf sling_linux_amd64.tar.gz \
&& rm -f sling_linux_amd64.tar.gz \
&& chmod +x sling
# Install using Scoop (Windows)
scoop bucket add sling https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Install using Python pip
pip install sling
After installation, verify that Sling is properly installed by checking its version:
# Check Sling version
sling --version
For more detailed installation instructions, visit the Sling CLI Getting Started Guide.
Setting Up Connections
Before we can export data from PostgreSQL to S3, we need to configure our source and target connections. Sling provides multiple ways to set up and manage connections securely.
PostgreSQL Connection Setup
You can set up a PostgreSQL connection using any of these methods:
Using sling conns set Command
# Set up PostgreSQL connection using individual parameters
sling conns set POSTGRES type=postgres host=localhost user=myuser database=mydb password=mypassword port=5432
# Or use a connection URL
sling conns set POSTGRES url="postgresql://myuser:mypassword@localhost:5432/mydb"
Using Environment Variables
# Set PostgreSQL connection using environment variable
export POSTGRES='postgresql://myuser:mypassword@localhost:5432/mydb'
Using Sling Environment File
Create or edit ~/.sling/env.yaml:
connections:
POSTGRES:
type: postgres
host: localhost
user: myuser
password: mypassword
port: 5432
database: mydb
schema: public # optional
S3 Connection Setup
For S3, you’ll need to provide AWS credentials and bucket information. Here’s how to set up the connection:
Using sling conns set Command
# Set up S3 connection using individual parameters
sling conns set S3 type=s3 bucket=my-bucket access_key_id=YOUR_ACCESS_KEY secret_access_key=YOUR_SECRET_KEY
# For specific region or endpoint
sling conns set S3 type=s3 bucket=my-bucket access_key_id=YOUR_ACCESS_KEY secret_access_key=YOUR_SECRET_KEY region=us-west-2
Using Environment Variables
# Set S3 connection using environment variables
export S3='{
"type": "s3",
"bucket": "my-bucket",
"access_key_id": "YOUR_ACCESS_KEY",
"secret_access_key": "YOUR_SECRET_KEY"
}'
Using Sling Environment File
Add to your ~/.sling/env.yaml:
connections:
S3:
type: s3
bucket: my-bucket
access_key_id: YOUR_ACCESS_KEY
secret_access_key: YOUR_SECRET_KEY
region: us-west-2 # optional
Testing Connections
After setting up your connections, verify them using the sling conns commands:
# List all configured connections
sling conns list
# Test PostgreSQL connection
sling conns test POSTGRES
# Test S3 connection
sling conns test S3
# Discover available tables in PostgreSQL
sling conns discover POSTGRES
For more details about connection configuration, refer to the Sling Environment Documentation.
Basic Data Export with CLI Flags
The quickest way to export data from PostgreSQL to S3 CSV files is using Sling’s CLI flags. Let’s look at some common usage patterns.
Simple Export Example
The most basic way to export data is using the sling run command with source and target specifications:
# Export a single table to CSV in S3
sling run \
--src-conn POSTGRES \
--src-stream "public.users" \
--tgt-conn S3 \
--tgt-object "data/users.csv"
Advanced CLI Options
For more complex scenarios, you can use additional flags:
# Export with specific columns and where clause
sling run \
--src-conn POSTGRES \
--src-stream "SELECT id, name, email FROM public.users WHERE created_at > '2024-01-01'" \
--tgt-conn S3 \
--tgt-object "data/filtered_users.csv" \
--tgt-options '{ "delimiter": "|", "header": true, "datetime_format": "YYYY-MM-DD" }'
# Export multiple tables matching a pattern
sling run \
--src-conn POSTGRES \
--src-stream "public.sales_*" \
--tgt-conn S3 \
--tgt-object "data/sales/{stream_table}.csv" \
--tgt-options '{ "file_max_bytes": 100000000 }'
For a complete list of available CLI flags and options, refer to the Sling CLI Flags documentation.
Advanced Data Export with YAML Configuration
While CLI flags are great for simple exports, YAML configuration files provide more flexibility and reusability for complex data export scenarios. Let’s explore how to use YAML configurations with Sling.
Basic Multi-Stream Example
Create a file named postgres_to_s3.yaml with the following content:
# Basic configuration for exporting multiple tables
source: POSTGRES
target: S3
defaults:
mode: full-refresh
target_options:
format: csv
header: true
datetime_format: YYYY-MM-DD HH:mm:ss
file_max_bytes: 100000000
streams:
public.users:
object: data/users/users.csv
select: [id, username, email, created_at]
public.orders:
object: data/orders/orders.csv
select: [order_id, user_id, total_amount, status, order_date]
Run the export using:
# Execute the replication configuration
sling run -r postgres_to_s3.yaml
Advanced Replication Example
Here’s a more complex example with multiple streams and custom options:
source: POSTGRES
target: S3
defaults:
mode: full-refresh
target_options:
format: csv
header: true
datetime_format: YYYY-MM-DD HH:mm:ss
file_max_bytes: 100000000
column_casing: snake
streams:
# Customer data with specific columns and transformations
public.customers:
object: 'data/customers/{YYYY}_{MM}_{DD}.csv'
select:
- customer_id
- name
- email
- status
- created_at
- updated_at
# Orders with custom SQL and options
public.orders:
mode: incremental
primary_key: [order_id]
update_key: created_at
object: 'data/orders/{part_year}/{part_month}'
sql: |
SELECT o.*, c.name as customer_name
FROM public.orders o
JOIN public.customers c ON o.customer_id = c.customer_id
WHERE o.created_at >= coalesce({incremental_value}, '2001-01-01')
target_options:
file_max_bytes: 50000000
For more details about replication configuration options, visit the Replication Documentation.
Using the Sling Platform
While the CLI is great for development and testing, the Sling Platform provides a user-friendly interface for managing and monitoring your data exports in production. Here’s how to use it:
Visual Editor
The Sling Platform includes a visual editor for creating and managing your replication configurations:

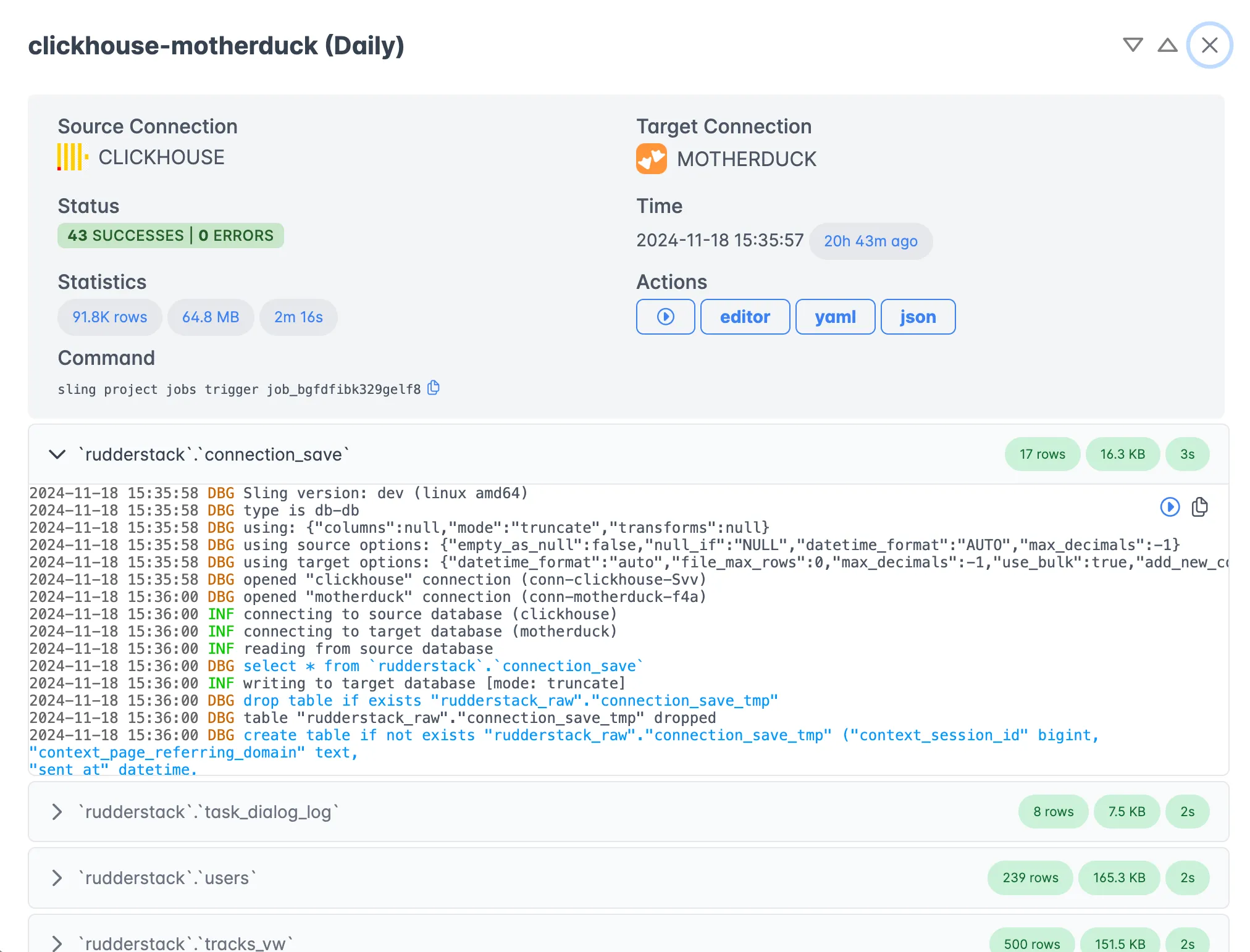
Execution Monitoring
Monitor your data exports in real-time with detailed execution statistics:
Best Practices and Tips
Here are some best practices to follow when using Sling for PostgreSQL to S3 CSV exports:
Connection Management
- Use environment variables for sensitive credentials
- Store connection strings securely
- Use SSL/TLS for database connections
- Test connections before running replications
Performance Optimization
- Use appropriate
file_max_bytesfor your use case - Consider using incremental mode for large tables
- Leverage runtime variables for dynamic file naming
- Monitor system resources during exports
- Use appropriate
Error Handling
- Set up proper monitoring and alerting
- Use descriptive error messages
- Implement retries for transient failures
- Keep logs for troubleshooting
Security
- Follow the principle of least privilege
- Rotate credentials regularly
- Encrypt sensitive data in transit
- Use appropriate S3 bucket policies
Additional Resources
For more information and examples, visit: