
Introduction
In today’s data-driven world, efficiently moving data between different systems is crucial for analytics, reporting, and data warehousing. One common requirement is transferring data from PostgreSQL databases to AWS S3 as JSON files, a format that offers excellent flexibility and interoperability. However, setting up this data pipeline traditionally involves multiple tools, complex configurations, and significant maintenance overhead.
Enter Sling, an open-source data movement tool that simplifies this process dramatically. In this guide, we’ll explore how to use Sling to efficiently transfer data from PostgreSQL to S3 JSON files, making your data pipeline both powerful and maintainable.
Traditional Data Pipeline Challenges
When building a data pipeline to transfer PostgreSQL data to S3 JSON files, organizations often face several challenges:
- Complex setup requiring multiple tools and dependencies (like AWS SDK, PostgreSQL drivers)
- Need for custom code to handle JSON serialization and data type conversions
- Performance bottlenecks when handling large datasets
- Difficulty in maintaining schema consistency
- Resource-intensive ETL processes
- Lack of monitoring and error handling
- High maintenance overhead
- Security concerns with AWS credentials management
These challenges often lead to brittle pipelines that are difficult to maintain and scale. Traditional approaches might involve writing custom scripts using tools like:
- AWS SDK for S3 operations
- PostgreSQL client libraries
- Custom JSON serialization logic
- Error handling and retry mechanisms
- Monitoring and logging systems
Let’s see how Sling addresses these issues with its unified approach.
Getting Started with Sling
The first step is to install Sling on your system. Sling provides multiple installation methods to suit your environment:
# Install using Homebrew (macOS)
brew install slingdata-io/sling/sling
# Install using curl (Linux)
curl -LO 'https://github.com/slingdata-io/sling-cli/releases/latest/download/sling_linux_amd64.tar.gz' \
&& tar xf sling_linux_amd64.tar.gz \
&& rm -f sling_linux_amd64.tar.gz \
&& chmod +x sling
# Install using Scoop (Windows)
scoop bucket add sling https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Install using Python pip
pip install sling
After installation, verify that Sling is properly installed by checking its version:
# Check Sling version
sling --version
For more detailed installation instructions, visit the Sling CLI Getting Started Guide.
Setting Up Connections
Before we can start moving data, we need to configure our source (PostgreSQL) and target (S3) connections. Sling provides multiple ways to manage these connections securely.
PostgreSQL Connection Setup
You can set up a PostgreSQL connection using any of these methods:
Using sling conns set Command
# Set up PostgreSQL connection using individual parameters
sling conns set POSTGRES type=postgres host=localhost user=myuser database=mydb password=mypassword port=5432
# Or use a connection URL
sling conns set POSTGRES url="postgresql://myuser:mypassword@localhost:5432/mydb"
Using Environment Variables
# Set PostgreSQL connection using environment variable
export POSTGRES='postgresql://myuser:mypassword@localhost:5432/mydb'
Using Sling Environment File
Create or edit ~/.sling/env.yaml:
connections:
POSTGRES:
type: postgres
host: localhost
user: myuser
password: mypassword
port: 5432
database: mydb
schema: public # optional
S3 Connection Setup
For S3, you’ll need to provide AWS credentials and bucket information. Here’s how to set up the connection:
Using sling conns set Command
# Set up S3 connection using individual parameters
sling conns set S3 type=s3 bucket=my-bucket access_key_id=YOUR_ACCESS_KEY secret_access_key=YOUR_SECRET_KEY
# For specific region or endpoint
sling conns set S3 type=s3 bucket=my-bucket access_key_id=YOUR_ACCESS_KEY secret_access_key=YOUR_SECRET_KEY region=us-west-2
Using Environment Variables
# Set S3 connection using environment variables
export S3='{
"type": "s3",
"bucket": "my-bucket",
"access_key_id": "YOUR_ACCESS_KEY",
"secret_access_key": "YOUR_SECRET_KEY"
}'
Using Sling Environment File
Add to your ~/.sling/env.yaml:
connections:
S3:
type: s3
bucket: my-bucket
access_key_id: YOUR_ACCESS_KEY
secret_access_key: YOUR_SECRET_KEY
region: us-west-2 # optional
Testing Connections
After setting up your connections, verify them using the sling conns commands:
# List all configured connections
sling conns list
# Test PostgreSQL connection
sling conns test POSTGRES
# Test S3 connection
sling conns test S3
# Discover available tables in PostgreSQL
sling conns discover POSTGRES
For more details about connection configuration, refer to the Sling Environment Documentation.
Basic Data Transfer with CLI Flags
The simplest way to transfer data from PostgreSQL to S3 JSON files is using Sling’s CLI flags. This method is perfect for quick transfers and testing.
Simple Transfer Example
# Transfer a single table to a JSON file in S3
sling run \
--src-conn POSTGRES \
--src-stream "public.users" \
--tgt-conn S3 \
--tgt-object "data/users.json"
Advanced CLI Options
# Transfer with custom SQL query and options
sling run \
--src-conn POSTGRES \
--src-stream "SELECT id, name, email, created_at FROM users WHERE created_at > '2023-01-01'" \
--tgt-conn S3 \
--tgt-object "data/recent_users.json" \
--tgt-options '{ "datetime_format": "YYYY-MM-DD, "file_max_bytes": 100000000 }'
For more details about CLI flags, visit the CLI Flags Documentation.
Advanced Data Transfer with Replication YAML
For more complex data transfer scenarios, Sling supports YAML-based replication configurations. This approach offers more control and is better suited for production environments.
Basic Replication Example
Create a file named postgres_to_s3.yaml:
source: POSTGRES
target: S3
defaults:
mode: full-refresh
target_options:
format: json
datetime_format: "YYYY-MM-DD"
file_max_bytes: 100000000
streams:
# Export all tables in schema 'private'
private.*:
object: 'data/private/{stream_table}.json'
mode: full-refresh
public.users:
object: data/users/users.json
public.orders:
object: data/orders/orders.json
primary_key: [order_id]
select:
- order_id
- user_id
- total_amount
- status
- created_at
Advanced Replication Example
Here’s a more complex example with multiple streams and custom options:
source: POSTGRES
target: S3
defaults:
mode: full-refresh
target_options:
format: json
datetime_format: "2006-01-02T15:04:05Z07:00"
file_max_bytes: 100000000
column_casing: snake
streams:
# Customer data with specific columns and transformations
public.customers:
object: 'data/customers/{YYYY}_{MM}_{DD}.json'
select:
- customer_id
- name
- email
- status
- created_at
- updated_at
# Orders with custom SQL and options
public.orders:
object: 'data/orders/{part_year}/{part_month}.json'
sql: |
SELECT o.*, c.name as customer_name
FROM public.orders o
JOIN public.customers c ON o.customer_id = c.customer_id
WHERE o.created_at >= coalesce({incremental_value}, '2001-01-01')
mode: incremental
primary_key: [order_id]
update_key: created_at
target_options:
file_max_bytes: 50000000
# Product catalog with all columns
public.products:
object: 'data/products.json'
To run a replication using a YAML file:
# Run the replication
sling run -r postgres_to_s3.yaml
For more information about replication configuration, visit:
Sling Platform Overview
While the CLI is powerful for local development and simple workflows, Sling also provides a comprehensive platform for managing data operations at scale. The Sling Platform offers:
Connection Management

Features include:
- Centralized credential management
- Connection testing and validation
- Access control and auditing
- Usage monitoring
Job Monitoring
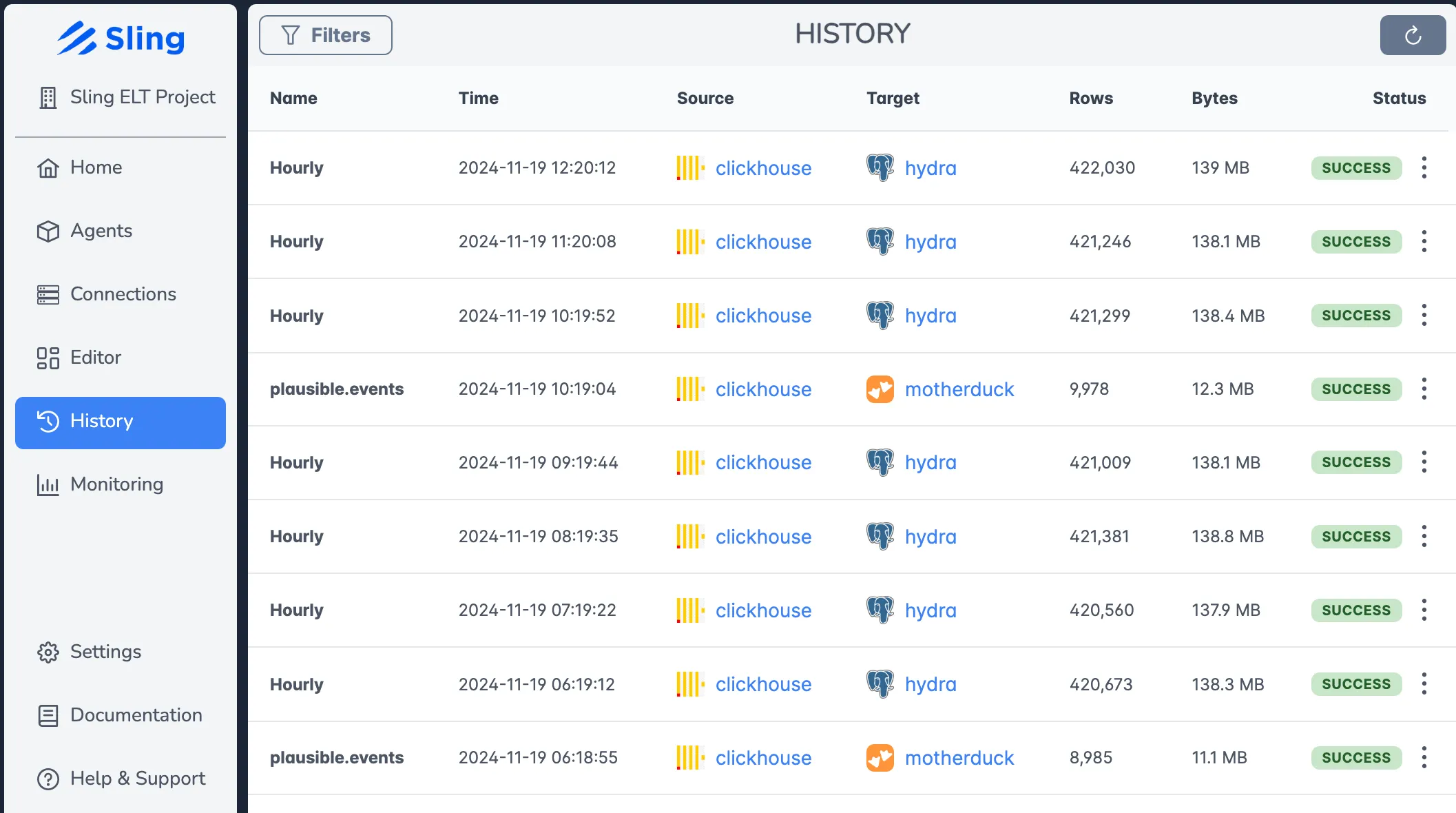
The monitoring interface provides:
- Real-time execution status
- Detailed logs and metrics
- Error reporting
- Performance analytics
Visual Editor

The visual editor allows you to:
- Create and edit replications
- Test configurations
- Schedule jobs
- Manage dependencies
For more information about the Sling Platform and its capabilities, visit the platform documentation.
Getting Started
Now that you understand how Sling can help with your PostgreSQL to S3 JSON data pipeline needs, here are some next steps:
- Install Sling CLI and try the basic examples
- Explore the documentation for advanced features
- Join the community for support and updates
- Consider the Sling Platform for enterprise needs
For more examples and detailed documentation, visit: