
Introduction
In today’s data-driven landscape, efficiently moving data from PostgreSQL databases to cloud storage solutions like Amazon S3 is a critical requirement for many organizations. When combined with the Parquet file format’s superior compression and query performance capabilities, this creates a powerful solution for data warehousing and analytics. However, setting up and maintaining such a data pipeline traditionally involves multiple tools, complex configurations, and significant overhead.
Enter Sling, a modern data movement tool that dramatically simplifies this process. In this guide, we’ll explore how to use Sling to efficiently transfer data from PostgreSQL to S3, storing it in the Parquet format for optimal performance and cost efficiency. We’ll cover everything from installation and setup to advanced configuration options, making your data pipeline both powerful and maintainable.
Sling: A Modern Solution
Sling is a modern data movement platform designed to simplify data operations between various sources and destinations. It provides both a powerful CLI tool and a comprehensive platform for managing data workflows.
Key Features
- Efficient Data Transfer: Optimized for performance with built-in parallelization and streaming capabilities
- Native Parquet Support: Direct conversion to Parquet format without intermediate steps
- Schema Handling: Automatic schema detection and evolution support
- Incremental Updates: Built-in support for incremental data loading
- Security: Secure credential management for both PostgreSQL and S3
Getting Started with Sling
Let’s begin by installing Sling on your system. Sling provides multiple installation methods to suit your environment:
# Install using Homebrew (macOS)
brew install slingdata-io/sling/sling
# Install using curl (Linux)
curl -LO 'https://github.com/slingdata-io/sling-cli/releases/latest/download/sling_linux_amd64.tar.gz' \
&& tar xf sling_linux_amd64.tar.gz \
&& rm -f sling_linux_amd64.tar.gz \
&& chmod +x sling
# Install using Scoop (Windows)
scoop bucket add sling https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Install using Python pip
pip install sling
After installation, verify that Sling is properly installed:
# Check Sling version
sling --version
For more detailed installation instructions, visit the Sling CLI Getting Started Guide.
Setting Up Connections
Before we can transfer data, we need to configure our source (PostgreSQL) and target (S3) connections. Sling provides multiple ways to set up and manage connections securely.
PostgreSQL Connection Setup
You can set up a PostgreSQL connection using one of these methods:
Using Environment Variables
The simplest way is to use environment variables:
# Set PostgreSQL connection using environment variable
export POSTGRES='postgresql://myuser:mypassword@localhost:5432/mydatabase'
Using the Sling CLI
Alternatively, use the sling conns set command:
# Set up PostgreSQL connection with individual parameters
sling conns set POSTGRES type=postgres host=localhost user=myuser database=mydatabase password=mypassword port=5432
# Or use a connection URL
sling conns set POSTGRES url="postgresql://myuser:mypassword@localhost:5432/mydatabase"
Using the Sling Environment File
You can also add the connection details to your ~/.sling/env.yaml file:
connections:
POSTGRES:
type: postgres
host: localhost
user: myuser
password: mypassword
port: 5432
database: mydatabase
schema: public
S3 Connection Setup
For Amazon S3, you’ll need to configure AWS credentials. Here are the available methods:
Using Environment Variables
# Set AWS credentials using environment variables
export AWS_ACCESS_KEY_ID='your_access_key'
export AWS_SECRET_ACCESS_KEY='your_secret_key'
export AWS_REGION='us-west-2' # optional, defaults to us-east-1
Using the Sling CLI
# Set up S3 connection with credentials
sling conns set S3 type=s3 access_key_id=your_access_key secret_access_key=your_secret_key region=us-west-2
Using the Sling Environment File
Add the S3 connection to your ~/.sling/env.yaml:
connections:
S3:
type: s3
access_key_id: your_access_key
secret_access_key: your_secret_key
region: us-west-2 # optional, defaults to us-east-1
Testing Connections
After setting up your connections, it’s important to verify they work correctly:
# Test the PostgreSQL connection
sling conns test POSTGRES
# Test the S3 connection
sling conns test S3
You can also explore the PostgreSQL database schema:
# List available tables in the public schema
sling conns discover POSTGRES -p 'public.*'
For more details about connection configuration and options, refer to:
Basic Data Transfer with CLI Flags
Once you have your connections set up, you can start transferring data from PostgreSQL to S3 using Sling’s CLI flags. Let’s look at some common usage patterns.
Simple Transfer Example
The most basic way to transfer data is using the sling run command with source and target specifications:
# Export a single table to S3 as Parquet
sling run \
--src-conn POSTGRES \
--src-stream "public.users" \
--tgt-conn S3 \
--tgt-object "s3://my-bucket/data/users.parquet"
Understanding CLI Flag Options
Sling provides various CLI flags to customize your transfer:
# Export with specific columns and where clause
sling run \
--src-conn POSTGRES \
--src-stream "SELECT id, name, email FROM users WHERE created_at > '2024-01-01'" \
--tgt-conn S3 \
--tgt-object "s3://my-bucket/data/filtered_users.parquet" \
--tgt-options '{ "compression": "snappy", "row_group_size": 100000 }'
# Export with custom Parquet options and table keys
sling run \
--src-conn POSTGRES \
--src-stream "public.orders" \
--tgt-conn S3 \
--tgt-object "s3://my-bucket/data/orders.parquet" \
--tgt-options '{ "file_max_bytes": 100000000, "compression": "snappy" }'
Using Runtime Variables
Sling supports runtime variables that can be used in your object paths and queries:
# Export multiple tables with runtime variables
sling run \
--src-conn POSTGRES \
--src-stream "public.sales_*" \
--tgt-conn S3 \
--tgt-object "s3://my-bucket/data/{stream_table}/{date_yyyy_mm_dd}.parquet" \
--tgt-options '{ "file_max_bytes": 100000000 }'
For a complete list of available CLI flags and runtime variables, refer to:
Advanced Data Transfer with Replication YAML
While CLI flags are great for simple transfers, YAML configuration files provide more flexibility and reusability for complex data transfer scenarios. Let’s explore how to use YAML configurations with Sling.
Basic Multi-Stream Example
Create a file named postgres_to_s3.yaml with the following content:
# Basic configuration for exporting multiple tables
source: POSTGRES
target: S3
defaults:
mode: full-refresh
target_options:
format: parquet
compression: snappy
file_max_bytes: 100000000
streams:
# Export users table with specific columns
public.users:
object: s3://my-bucket/data/users/{YYYY}_{MM}_{DD}.parquet
select: [id, name, email, created_at]
# Export orders table with primary key and column selection
public.orders:
object: s3://my-bucket/data/orders/{YYYY}_{MM}_{DD}.parquet
target_options:
format: parquet
compression: gzip
Advanced Configuration Example
Here’s a more complex example with multiple streams and advanced options:
source: POSTGRES
target: S3
defaults:
mode: incremental
source_options:
add_new_columns: true
target_options:
format: parquet
compression: snappy
row_group_size: 100000
file_max_bytes: 100000000
streams:
# Export all tables in sales schema
sales.*:
object: s3://my-bucket/data/{stream_schema}/{stream_table}.parquet
mode: full-refresh
target_options:
format: parquet
compression: snappy
file_max_bytes: 500000000
# Incremental export of customer transactions (partitioning)
public.transactions:
object: s3://my-bucket/data/transactions/{part_year}/{part_month}
sql: |
select transaction_id, customer_id, amount, status, created_at
from public.transactions
where created_at > coalesce({incremental_val}, '2001-01-01)
# Export specific customer data with custom query
public.customers:
object: s3://my-bucket/data/customers.parquet
mode: full-refresh
query: |
SELECT
c.customer_id,
c.name,
c.email,
COUNT(o.order_id) as total_orders,
SUM(o.total_amount) as lifetime_value
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id, c.name, c.email
To run a replication configuration:
# Execute the replication configuration
sling run -r postgres_to_s3.yaml
For more details about replication configuration options, refer to:
Using the Sling Platform UI
While the CLI is powerful for automation and scripting, the Sling Platform provides a user-friendly web interface for managing and monitoring your data transfers.
Key Platform Features
The Sling Platform offers several advantages:
- Visual Replication Editor: Create and edit replication configurations with a user-friendly interface
- Real-time Monitoring: Track the progress of your data transfers in real-time
- History and Logs: View detailed execution history and logs for troubleshooting
- Team Collaboration: Share connections and configurations with team members
- Scheduling: Set up recurring transfers with flexible scheduling options
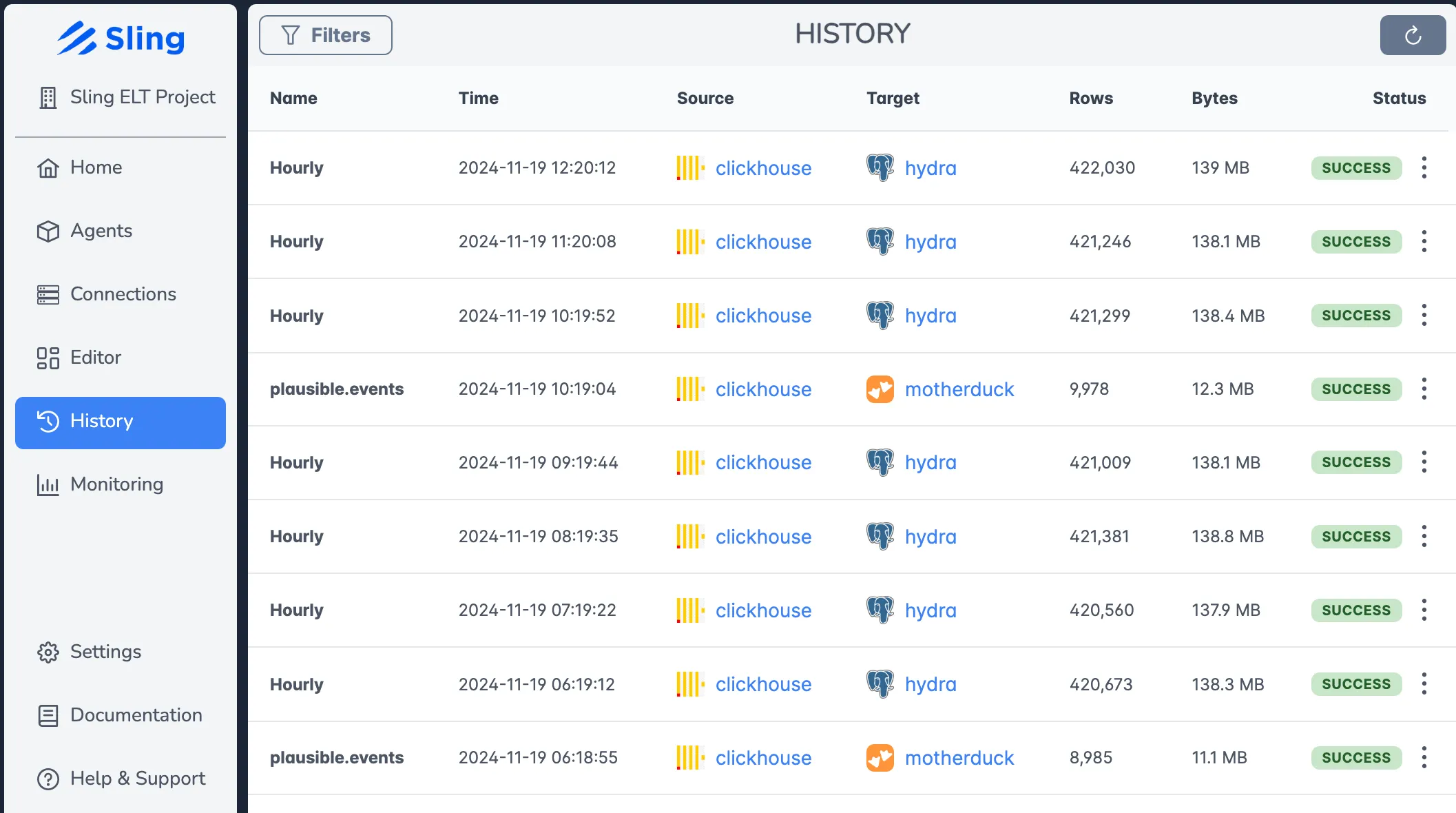
Getting Started with the Platform
To get started with the Sling Platform:
- Visit platform.slingdata.io to create an account
- Follow the onboarding process to set up your workspace
- Create your PostgreSQL and S3 connections
- Create your first replication using the visual editor
- Monitor your transfers in real-time
For more information about the Sling Platform, visit the Platform Documentation.
Getting Started and Next Steps
Now that you understand how to use Sling for transferring data from PostgreSQL to S3 in Parquet format, here are some next steps to explore:
Additional Resources
- Database to File Examples
- Replication Modes Documentation
- Source Options Reference
- Target Options Reference
Best Practices
- Start Small: Begin with a single table and simple configuration
- Test Thoroughly: Use the
--dry-runflag to validate your configuration - Monitor Performance: Use the platform’s monitoring features to optimize your transfers
- Use Version Control: Store your replication YAML files in version control
- Implement Security: Follow AWS best practices for S3 bucket policies and IAM roles
Next Steps
- Set up your first PostgreSQL to S3 transfer using the CLI
- Create a more complex replication using YAML configuration
- Explore the Sling Platform for visual configuration and monitoring
- Join the Sling community to share experiences and get help
With Sling, you can efficiently manage your data pipeline needs while maintaining flexibility and control over your data movement processes.