
Introduction
Moving data between SQL Server databases is a common requirement in many organizations, whether for system migrations, data consolidation, or maintaining development and testing environments. While SQL Server provides native tools for data migration, they often require complex configuration and can be challenging to automate and maintain.
Enter Sling, a modern data integration tool that simplifies the process of moving data between SQL Server databases. With its intuitive CLI and powerful platform features, Sling makes database migrations and synchronization tasks straightforward and efficient.
In this article, we’ll explore how to use Sling to:
- Set up connections to source and target SQL Server databases
- Configure and execute data transfers using both CLI and YAML approaches
- Leverage advanced features for optimizing data movement
- Monitor and manage ongoing replication tasks
Whether you’re a database administrator, developer, or data engineer, you’ll find Sling’s approach to SQL Server data migration both powerful and refreshingly simple.
Understanding SQL Server Data Migration Challenges
Moving data between SQL Server databases traditionally involves several complex steps and considerations. Let’s look at some common challenges that organizations face when attempting SQL Server to SQL Server migrations:
Traditional Methods and Their Limitations
SQL Server Integration Services (SSIS)
- Requires installation of Visual Studio and SSIS packages
- Complex to maintain and version control
- Limited automation capabilities
- Steep learning curve
Backup and Restore
- Time-consuming for large databases
- Requires significant storage space
- All-or-nothing approach
- Network bandwidth intensive
Bulk Copy Program (BCP)
- Limited transformation capabilities
- Manual schema management
- Complex error handling
- No built-in scheduling
Common Migration Challenges
- Schema Compatibility: Ensuring table structures match between source and target
- Data Type Mappings: Managing differences in column data types
- Performance Impact: Minimizing the load on production systems
- Transaction Consistency: Maintaining data integrity during transfers
- Incremental Updates: Efficiently handling changes after initial load
- Error Recovery: Gracefully handling and recovering from failures
These challenges often lead to time-consuming manual processes, increased risk of errors, and significant operational overhead. This is where Sling comes in, offering a modern approach to database migrations that addresses these pain points with its streamlined workflow and robust feature set.
Getting Started with Sling
Let’s begin by installing Sling on your system. Sling provides multiple installation options to suit different operating systems and preferences.
Installation
Choose the installation method that best suits your environment:
# Install using Homebrew (macOS)
brew install slingdata-io/sling/sling
# Install using curl (Linux)
curl -LO 'https://github.com/slingdata-io/sling-cli/releases/latest/download/sling_linux_amd64.tar.gz' \
&& tar xf sling_linux_amd64.tar.gz \
&& rm -f sling_linux_amd64.tar.gz \
&& chmod +x sling
# Install using Scoop (Windows)
scoop bucket add sling https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Install using Python pip
pip install sling
For more detailed installation instructions, visit the Sling CLI Getting Started Guide.
Verifying Installation
After installation, verify that Sling is properly installed by checking its version:
# Check Sling version
sling --version
You should see the current version number displayed, confirming that Sling is ready to use.
Setting Up Database Connections
Before we can start moving data, we need to configure connections to both our source and target SQL Server databases. Sling provides multiple ways to manage database connections securely. Please see details about SQL Server here.
Using Environment Variables
The simplest way to set up connections is through environment variables. For SQL Server connections, you’ll need to provide the connection string in the following format:
# Source database connection
export SRC_SQLSERVER="sqlserver://username:password@host:port/database?options"
# Target database connection
export TGT_SQLSERVER="sqlserver://username:password@host:port/database?options"
For more information about environment variables, visit the Sling Environment documentation.
Using the Sling Connections Command
Alternatively, you can use the sling conns set command to manage your connections. This method stores connection information securely in the Sling environment file:
# Set up source SQL Server connection using `sling conns`
sling conns set src_sqlserver type=sqlserver \
host=<host> user=<user> database=<database> \
password=<password> port=<port>
Testing Connections
After setting up your connections, it’s important to verify that they work correctly:
# Test source connection
sling conns test src_sqlserver
# Test target connection
sling conns test tgt_sqlserver
Discovering Available Tables
You can explore the available tables in your SQL Server databases using the discover command:
# List available tables in source database
sling conns discover src_sqlserver
This will show you a list of available schemas and tables that you can use in your data migration tasks.
For more detailed information about SQL Server connections, visit the SQL Server Connection documentation.
Basic Data Synchronization with CLI Flags
Sling provides a straightforward way to sync data between SQL Server databases using CLI flags. Let’s look at some examples, starting with basic usage and moving to more advanced scenarios.
Simple Table Replication
Here’s a basic example of copying a table from one SQL Server database to another:
# Copy a single table with default settings
sling run \
--src-conn src_sqlserver \
--src-stream "marketing.*" \
--tgt-conn tgt_sqlserver \
--tgt-object "marketing.{stream_table}"
This command will copy all the tables in schema marketing from the source to the target database, automatically creating the table if it doesn’t exist.
Advanced Replication with Options
For more control over the replication process, you can use additional CLI flags:
# Advanced replication with multiple options
sling run \
--src-conn src_sqlserver \
--src-stream "sales.orders" \
--src-query "SELECT * FROM sales.orders WHERE order_date >= '2023-01-01'" \
--tgt-conn tgt_sqlserver \
--tgt-object "sales.orders_2023" \
--mode incremental \
--primary-key order_id \
--update-key order_date \
--table-keys "{ unique: [order_number] }" # sets unique index
This example demonstrates several advanced features:
- Custom SQL query for source data
- Incremental mode with primary and update keys
- Custom table key configuration
Bulk Loading with BCP
Sling automatically leverages SQL Server’s Bulk Copy Program (BCP) for efficient data loading when possible. BCP is used by default when:
- The
bcputility is found in your system PATH - The target option
use_bulkis not explicitly set tofalse(it defaults totrue)
Here’s an example that explicitly enables BCP loading:
# Enable BCP loading with specific options
sling run \
--src-conn src_sqlserver \
--src-stream "sales.large_table" \
--tgt-conn tgt_sqlserver \
--tgt-object "sales.large_table" \
--target-options "{ use_bulk: true}"
BCP significantly improves loading performance for large datasets by:
- Using native SQL Server bulk loading protocols
- Minimizing transaction log usage
- Reducing network overhead
- Optimizing memory usage
If you need to disable BCP loading for any reason, you can do so with:
# Disable BCP loading
sling run \
--src-conn src_sqlserver \
--src-stream "sales.table" \
--tgt-conn tgt_sqlserver \
--tgt-object "sales.table" \
--target-options "{ use_bulk: false }"
For a complete list of available CLI flags and their usage, refer to the CLI Flags Overview in the documentation.
Advanced Data Synchronization with YAML
While CLI flags are great for simple operations, YAML configuration files provide a more powerful and maintainable way to define complex data synchronization tasks. Let’s explore how to use YAML configurations for SQL Server to SQL Server replication.
Basic Multi-Stream Example
Here’s a basic example of replicating multiple tables using a YAML configuration:
# Basic multi-stream replication configuration
source: src_sqlserver
target: tgt_sqlserver
defaults:
mode: full-refresh
target_options:
add_new_columns: true
use_bulk: true
streams:
# all the tables in marketing
marketing.*:
object: marketing.{stream_table}
sales.customers:
object: sales.customers
primary_key: customer_id
sales.orders:
object: sales.orders
primary_key: order_id
sales.order_items:
object: sales.order_items
primary_key: [order_id, item_id]
Save this configuration as sqlserver_to_sqlserver.yaml and run it with:
# Run the replication using the YAML config
sling run -r sqlserver_to_sqlserver.yaml
Complex Multi-Stream Example
Here’s a more complex example that showcases advanced features:
# Complex multi-stream replication configuration
source: src_sqlserver
target: tgt_sqlserver
defaults:
mode: incremental
target_options:
add_new_columns: true
column_casing: snake
streams:
sales.customers:
object: sales.customers_new
primary_key: customer_id
update_key: last_modified_date
select: [ -sensitive_data ] # Exclude this column, add all other ones
target_options:
table_keys:
unique: [ email ]
sales.orders:
object: sales.orders_new
primary_key: order_id
update_key: order_date
sql: |
SELECT
o.*,
c.customer_name,
c.customer_email
FROM sales.orders o
JOIN sales.customers c ON o.customer_id = c.customer_id
WHERE o.order_date >= '2023-01-01'
sales.order_items:
object: sales.order_items_new
primary_key: [order_id, item_id]
update_key: last_modified_date
# force cast column types
columns:
order_id: bigint
item_id: int
product_id: varchar(50)
quantity: int
unit_price: decimal(10,2)
total_amount: decimal(10,2)
This complex example demonstrates:
- Column exclusion
- Custom SQL queries with joins
- Table keys (primary, unique)
- Column type specifications
- Snake case column naming
For more information about replication configuration options, refer to:
The Sling Platform
While the CLI is powerful for local development and simple tasks, the Sling Platform provides a comprehensive web interface for managing and monitoring your data operations at scale.
Platform Components
The Sling Platform consists of several key components:
Web Interface
The web interface provides a user-friendly environment for:
- Managing database connections
- Creating and editing replication configurations
- Monitoring job execution
- Viewing detailed logs and statistics
- Collaborating with team members

Agent Architecture
Sling uses a distributed agent architecture that:
- Runs in your own infrastructure
- Provides secure access to your data sources
- Scales horizontally for increased throughput
- Supports both development and production environments
Job Management
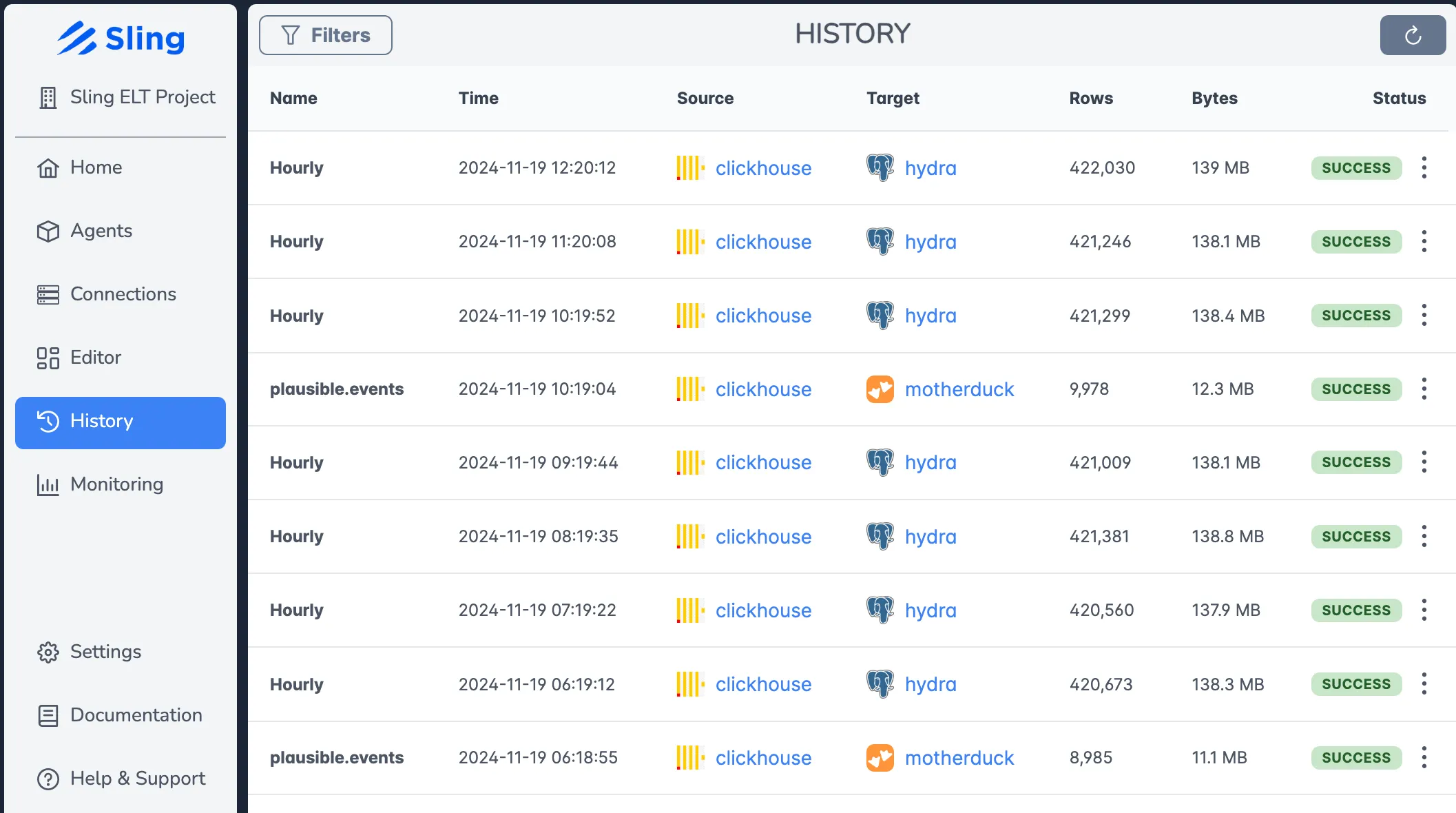
The platform includes comprehensive job management features:
- Scheduling and orchestration
- Real-time monitoring
- Detailed execution history
- Error notifications and alerts
For more information about the Sling Platform and its features, visit the Platform Getting Started Guide.
Getting Started Guide
Now that we’ve covered the various aspects of using Sling for SQL Server data migration, let’s summarize the steps to get started:
Install Sling
- Choose the appropriate installation method for your system
- Verify the installation with
sling --version - Review the CLI Getting Started Guide
Set Up Connections
- Configure source and target SQL Server connections
- Use environment variables or
sling conns set - Test connections with
sling conns test - Explore available tables with
sling conns discover
Choose Your Approach
- For simple tasks, use CLI flags
- For complex scenarios, create YAML configurations
- Consider using the Sling Platform for enterprise needs
Start Small
- Begin with a single table replication
- Test thoroughly in a non-production environment
- Gradually add more complex features
- Monitor performance and adjust as needed
Additional Resources
To learn more about Sling and its capabilities, check out these resources:
- Database to Database Examples
- SQL Server Connection Guide
- Replication Concepts
- Replication Modes
- Platform Documentation
With Sling, you can streamline your SQL Server data migration processes, making them more efficient, reliable, and maintainable. Whether you’re moving a single table or orchestrating complex data workflows, Sling provides the tools and flexibility you need to get the job done effectively.