
Introduction
In today’s data-driven world, efficiently moving data between different storage formats and databases is crucial for businesses. One common scenario is migrating data from Parquet files, a popular columnar storage format, to SQL Server databases. While this process traditionally involves multiple steps and complex tooling, Sling offers a streamlined solution that makes this data migration effortless.
Sling is a modern data movement and transformation platform that excels at simplifying complex data operations. Whether you’re dealing with a few megabytes or terabytes of data, Sling provides both a powerful CLI tool and a comprehensive platform to handle your data migration needs efficiently.
Key Features
- Simple Setup: Get started in minutes with straightforward installation and configuration
- Flexible Connectivity: Native support for both Parquet files and SQL Server
- Powerful Transformations: Built-in data transformation capabilities during migration
- Production Ready: Enterprise-grade reliability with monitoring and error handling
- Multiple Interfaces: Choose between an intuitive CLI or a feature-rich web platform
In this guide, we’ll walk through the process of using Sling to migrate your Parquet data to SQL Server, from basic setup to advanced configurations. Whether you’re a data engineer, developer, or database administrator, you’ll find Sling’s approach both powerful and refreshingly simple.
Understanding the Challenge
Migrating data from Parquet files to SQL Server traditionally involves several complex steps and challenges. Let’s explore why this process can be cumbersome and how Sling addresses these pain points.
Traditional Approaches
Without specialized tools, the typical process involves:
- Multiple Tools: Using separate tools for reading Parquet files and writing to SQL Server
- Custom Code: Writing and maintaining scripts to handle the data transformation
- Manual Schema Mapping: Defining and mapping data types between Parquet and SQL Server
- Performance Tuning: Optimizing batch sizes and connection settings
- Error Handling: Implementing robust error handling and retry logic
This approach not only requires significant development effort but also creates maintenance overhead and potential points of failure.
Common Pain Points
- Complex Setup: Traditional ETL tools often require extensive configuration and infrastructure
- Limited Flexibility: Many solutions lack support for various data types or complex transformations
- Performance Issues: Inefficient data loading can lead to long migration times
- Resource Intensive: High memory usage when processing large Parquet files
- Maintenance Burden: Managing dependencies and keeping custom scripts updated
The Need for a Better Solution
These challenges highlight the need for a modern, streamlined approach to data migration. Sling addresses these pain points by providing:
- Unified Interface: A single tool for both reading Parquet and writing to SQL Server
- Automatic Schema Handling: Smart data type mapping and schema management
- Optimized Performance: Efficient data loading with built-in performance optimizations
- Minimal Setup: Quick installation and simple configuration
- Production Ready: Enterprise-grade reliability out of the box
With Sling, what used to be a complex, multi-step process becomes a straightforward operation that can be set up in minutes.
Getting Started with Sling
Getting started with Sling is straightforward. Let’s walk through the installation process and initial setup.
Installation
Sling offers multiple installation methods to suit your environment:
# Install using Homebrew (macOS)
brew install slingdata-io/sling/sling
# Install using curl (Linux)
curl -LO 'https://github.com/slingdata-io/sling-cli/releases/latest/download/sling_linux_amd64.tar.gz' \
&& tar xf sling_linux_amd64.tar.gz \
&& rm -f sling_linux_amd64.tar.gz \
&& chmod +x sling
# Install using Scoop (Windows)
scoop bucket add sling https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Install using Python pip
pip install sling
After installation, verify that Sling is properly installed:
# Check Sling version
sling --version
Setting Up Connections
Before we can start migrating data, we need to configure our source (local storage for Parquet files) and target (SQL Server) connections. Let’s look at the different ways to set up these connections.
Using the CLI
The quickest way to set up connections is using the sling conns set command:
# Set up local storage connection (automatically configured)
sling conns set local
# Set up SQL Server connection
sling conns set SQLSERVER type=sqlserver \
host=your-server.database.windows.net \
user=your_username \
database=your_database \
password=your_password \
port=1433
Using Environment Variables
You can also set up connections using environment variables:
# SQL Server connection using URL format
export SQLSERVER='sqlserver://your_username:[email protected]:1433?database=your_database'
# Or using JSON format
export SQLSERVER='{
"type": "sqlserver",
"host": "your-server.database.windows.net",
"user": "your_username",
"password": "your_password",
"database": "your_database",
"port": "1433"
}'
Using YAML Configuration
For a more permanent setup, you can define your connections in the ~/.sling/env.yaml file:
connections:
SQLSERVER:
type: sqlserver
host: your-server.database.windows.net
user: your_username
database: your_database
password: your_password
port: 1433
# Optional parameters
encrypt: true
trust_server_certificate: true
schema: dbo
Testing Connections
After setting up your connections, it’s good practice to test them:
# Test local storage connection (built-in)
sling conns test local
# Test SQL Server connection
sling conns test sqlserver
Discovering Available Streams
You can explore available streams (tables/files) in your connections:
# List Parquet files in local storage
sling conns discover local
# List tables in SQL Server
sling conns discover sqlserver
For more details about connection configuration options, refer to the documentation for local storage and SQL Server connections.
Basic Data Migration
With our connections set up, let’s explore how to perform basic data migrations from Parquet files to SQL Server using Sling’s CLI.
Simple Migration Commands
The most basic way to migrate data is using the sling run command with CLI flags:
# Migrate a single Parquet file to SQL Server
sling run \
--src-conn local \
--src-stream "file://data/users.parquet" \
--tgt-conn sqlserver \
--tgt-object "dbo.users"
# Migrate multiple Parquet files using wildcards
sling run \
--src-conn local \
--src-stream "file://data/*.parquet" \
--tgt-conn sqlserver \
--tgt-object "dbo.{stream_file_name}"
Understanding the Command Structure
Let’s break down the components of a basic migration command:
--src-conn: The source connection name (local for Parquet files)--src-stream: The path to the Parquet file(s), prefixed withfile://--tgt-conn: The target connection name (sqlserver)--tgt-object: The target table name, can include runtime variables
Monitoring Progress
Sling provides real-time progress information during the migration:
# Enable detailed logging
sling run \
--src-stream "file://data/users.parquet" \
--tgt-conn sqlserver \
--tgt-object "dbo.users" \
--debug
Basic Options
You can customize the migration behavior with additional flags:
# Set the migration mode
sling run \
--src-stream "file://data/users.parquet" \
--tgt-conn sqlserver \
--tgt-object "dbo.users" \
--mode full-refresh \
--target-options '{"table_keys": {"primary_key": ["id"]}}' \
--source-options '{"empty_as_null": true}'
For more details about available CLI flags and options, refer to the CLI flags documentation.
Advanced Configuration
While CLI flags are great for simple migrations, Sling’s replication YAML files provide more advanced configuration options for complex data migration scenarios.
Basic Replication YAML
Here’s a basic example of a replication YAML file (local_to_sqlserver.yaml):
# Source and target connections
source: local
target: sqlserver
# Default settings for all streams
defaults:
mode: full-refresh
source_options:
empty_as_null: true
target_options:
column_casing: snake
add_new_columns: true
# Stream configurations
streams:
# Single Parquet file migration
"file://data/users.parquet":
object: dbo.users
target_options:
table_keys:
primary_key: [id]
# Multiple Parquet files with pattern matching
"file://data/transactions/*.parquet":
object: dbo.transactions
target_options:
table_keys:
primary_key: [transaction_id]
Advanced Replication YAML
Here’s a more complex example showcasing advanced features:
# Source and target connections
source: local
target: sqlserver
# Environment variables
env:
data_dir: /path/to/data
my_schema: analytics
year: ${YEAR} # from env var
month: ${MONTH} # from env var
# Default settings
defaults:
mode: incremental
source_options:
empty_as_null: true
datetime_format: "YYYY-MM-DD HH:mm:ss"
target_options:
column_casing: snake
add_new_columns: true
# Stream configurations
streams:
# Customer data with transformations
"file://{data_dir}/customers/*.parquet":
object: "{my_schema}.customers"
columns:
customer_id: varchar(50)
email: varchar(255)
created_at: datetime
transforms:
email: lower
target_options:
table_keys:
primary_key: [customer_id]
# Order data with custom SQL and runtime variables
"file://{data_dir}/orders/{year}/{month}/*.parquet":
object: "{my_schema}.orders"
mode: incremental
primary_key: [order_id]
target_options:
table_keys:
index: [department_id]
Running Replications
To run a replication using a YAML file:
# Run the replication
sling run -r local_to_sqlserver.yaml
# Run with additional options
sling run -r local_to_sqlserver.yaml --debug
For more details about replication configuration options, refer to:
Sling Platform Overview
While the CLI is powerful for local development and automation, the Sling Platform provides a user-friendly web interface for managing your data migrations at scale.
Key Platform Features
The Sling Platform offers several advantages over the CLI:
- Visual Interface: Intuitive UI for creating and managing data workflows
- Team Collaboration: Share connections and configurations across your team
- Monitoring Dashboard: Real-time monitoring and alerting
- Scheduling: Built-in job scheduling and orchestration
- Version Control: Track changes to your replication configurations
- Access Control: Role-based access control for team members
Platform Components
Connections Management
The platform provides a centralized place to manage all your connections:

Visual Editor
Create and edit replication configurations with a visual editor:

Monitoring and Logs
Monitor your data migrations in real-time:
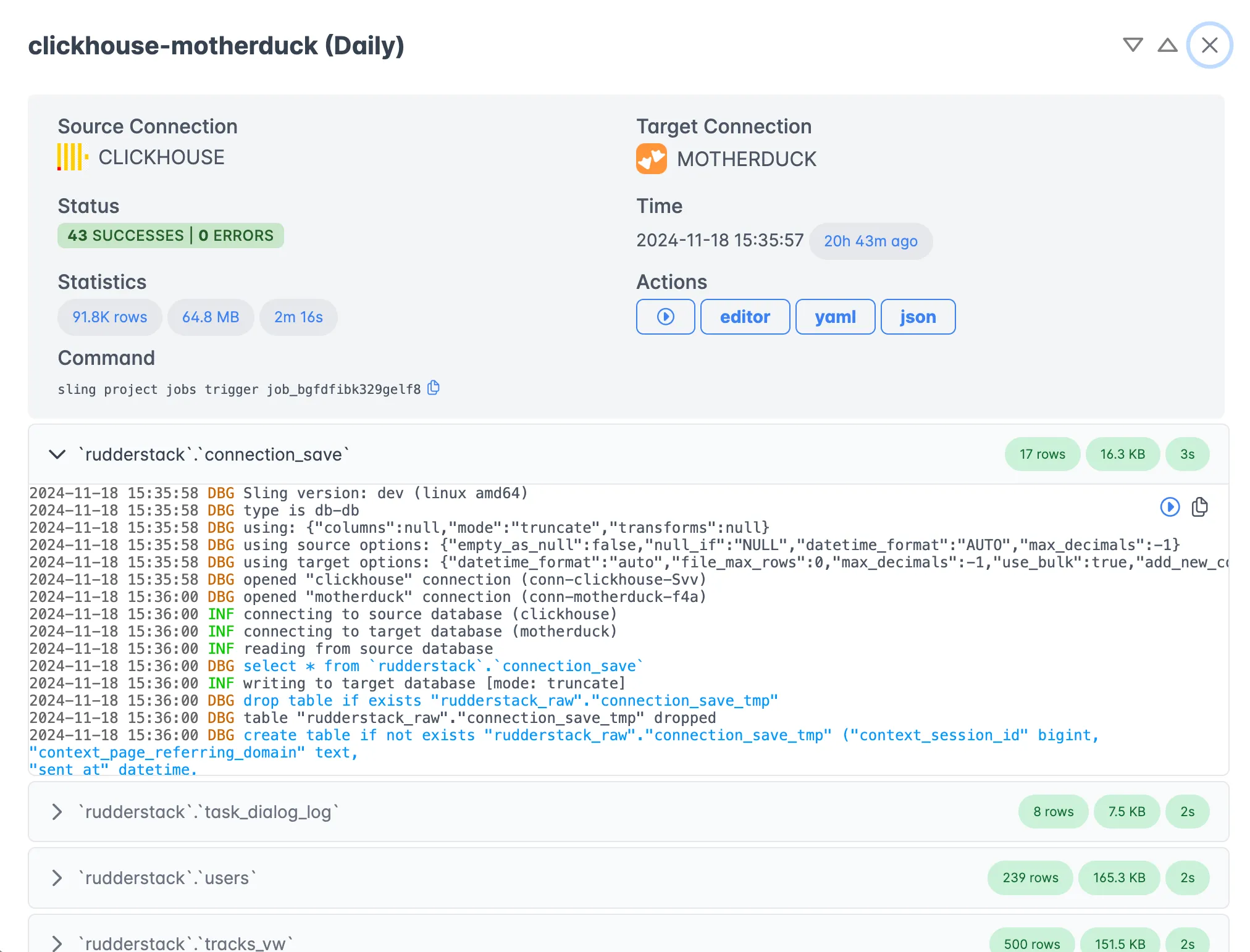
When to Use Platform vs CLI
Choose the platform when you need:
- Team collaboration features
- Centralized connection management
- Visual workflow creation
- Built-in monitoring and alerting
- Scheduled executions
Stick with the CLI for:
- Local development and testing
- CI/CD pipeline integration
- Quick one-off migrations
- Automated scripts and cron jobs
For more information about the Sling Platform, visit the platform documentation.
Best Practices and Tips
When migrating data from Parquet to SQL Server using Sling, consider these best practices:
Performance Optimization
- Batch Size: Adjust batch sizes based on your data volume and system resources
- Compression: Use appropriate compression options for large datasets
- Indexing: Consider creating indexes after the initial data load
- Memory Usage: Monitor and adjust memory usage for large migrations
Production Deployment
- Environment Variables: Use environment variables for sensitive information
- Monitoring: Enable detailed logging for production migrations
- Backup: Always have a backup strategy before large migrations
- Testing: Test migrations with a subset of data first
Common Patterns
- Incremental Loading: Use incremental mode for regular data updates
- Schema Evolution: Enable
add_new_columnsfor handling schema changes - Data Validation: Use transforms for data cleaning and validation
- Error Handling: Implement proper error handling in your workflows
Getting Started and Next Steps
Now that you understand how to use Sling for migrating Parquet data to SQL Server, here are some next steps:
- Start Small: Begin with a simple migration to familiarize yourself with Sling
- Explore Features: Try out different configuration options and transforms
- Automate: Set up automated workflows for regular data migrations
- Scale Up: Move to the Sling Platform for larger, team-based operations
Additional Resources
- File to Database Examples
- Database to Database Examples
- Replication Concepts
- CLI Documentation
- Platform Documentation
Community and Support
Join the Sling community to get help and share your experiences:
- Visit the documentation for detailed guides
- Follow best practices and examples from the community
- Reach out to support for enterprise-specific needs
With Sling, you can transform complex data migrations into simple, automated workflows. Whether you’re working with small datasets or enterprise-scale migrations, Sling provides the tools and flexibility you need to get the job done efficiently.