
Introduction
Last updated: June 2026
Data transfer between different database systems is a common requirement in modern data architectures. While Snowflake excels as a cloud data warehouse with its scalability and performance, PostgreSQL remains a popular choice for operational databases and analytics. However, setting up an efficient and reliable data pipeline between these systems traditionally involves complex ETL processes, custom scripts, and ongoing maintenance.
Enter Sling: an open-source data integration tool that simplifies this process dramatically. In this comprehensive guide, we’ll walk through how to use Sling to create a robust data pipeline from Snowflake to PostgreSQL, eliminating the complexity typically associated with such tasks.
Why Transfer Data from Snowflake to PostgreSQL?
Before diving into the technical details, let’s understand some common scenarios where you might need to transfer data from Snowflake to PostgreSQL:
- Application Backend: While Snowflake serves as your data warehouse, your applications might need specific datasets in PostgreSQL for faster access and lower costs
- Analytics Environment: Creating a dedicated PostgreSQL analytics database for specific teams or use cases
- Data Sharing: Providing data access to external systems or partners that prefer PostgreSQL
- Cost Optimization: Moving less frequently accessed data to PostgreSQL to optimize Snowflake costs
Traditional approaches to this data transfer might involve:
- Writing custom Python scripts using multiple libraries
- Managing complex authentication and connection handling
- Implementing error handling and retry logic
- Dealing with schema changes and data type mappings
- Setting up monitoring and logging
Sling simplifies all of these aspects with its intuitive CLI and configuration-based approach.
Moving in the opposite direction or between other engines? The guides on exporting PostgreSQL to Snowflake and moving SQL Server to Snowflake follow the same pattern as this one. Let’s see how to set it up.
Installing Sling
Getting started with Sling is straightforward. You can install it using various package managers depending on your operating system:
# macOS / Linux
curl -fsSL https://slingdata.io/install.sh | bash
# Windows
irm https://slingdata.io/install.ps1 | iex
# Python
pip install sling
After installation, verify that Sling is properly installed by checking its version:
# Check Sling version
sling --version
For more detailed installation instructions, visit the Sling CLI Getting Started guide.
Setting Up Connections
Before we can transfer data, we need to configure both our Snowflake source and PostgreSQL target connections. Sling provides multiple ways to manage connections, including environment variables and YAML configuration files.
Using Environment Variables
The simplest way to set up connections is using the sling conns set command. This command will prompt you for the necessary connection details and securely store them:
# Set up Snowflake connection
sling conns set snowflake_source type=snowflake account=<account> user=<user> database=<database> password=<password> role=<role>
# Set up PostgreSQL connection
sling conns set postgres_target type=postgres host=<host> user=<user> database=<database> password=<password> port=<port>
Using YAML Configuration
Alternatively, you can define your connections in a YAML file. Create an env.yaml file with the following structure:
# Connection configuration for Snowflake source
connections:
snowflake_source:
type: snowflake
account: your_account_id
warehouse: your_warehouse
database: your_database
schema: your_schema
username: your_username
password: ${SNOWFLAKE_PASSWORD} # Use environment variable for sensitive data
role: your_role
postgres_target:
type: postgres
host: your_host
port: 5432
database: your_database
schema: public
username: your_username
password: ${POSTGRES_PASSWORD} # Use environment variable for sensitive data
For enhanced security, we recommend using environment variables for sensitive information like passwords. You can reference them in your YAML file using the ${VARIABLE_NAME} syntax.
For more details about connection configuration, refer to:
Transferring Data with Sling
Sling offers two primary methods for transferring data: using CLI flags for quick operations and using YAML configuration files for more complex scenarios.
Using CLI Flags
For simple data transfers, you can use CLI flags to specify your source and target configurations:
# Basic example: Transfer a single table
sling run \
--src-connsnowflake_source \
--src-stream "sales.customers" \
--tgt postgres_target \
--tgt-stream "public.customers"
# Complex example: Transfer with additional options
sling run \
--src-connsnowflake_source \
--src-stream "sales.orders" \
--src-options '{ "select": "order_id, customer_id, amount, created_at", "table_keys": ["order_id"] }' \
--tgt postgres_target \
--tgt-stream "public.orders" \
--tgt-options '{ "column_casing": "snake", "add_new_columns": true }'
For more information about available CLI flags, visit the CLI Flags Overview.
Using Replication YAML
For more complex data transfer scenarios, especially when dealing with multiple tables or requiring specific configurations, using a replication YAML file is recommended. Create a file named snowflake_to_postgres.yaml:
# Basic example with multiple streams
source: snowflake_source
target: postgres_target
streams:
sales.customers:
object: public.customers
mode: full-refresh
sales.orders:
object: public.orders
mode: full-refresh
Incremental Mode
source: snowflake_source
target: postgres_target
defaults:
mode: incremental
target_options:
column_casing: snake
add_new_columns: true
streams:
sales.customers:
object: public.customers
primary_key: [customer_id]
select: [customer_id, name, email, created_at]
update_key: created_at
sales.orders:
object: public.orders
primary_key: [order_id]
select: [order_id, customer_id, amount, status]
update_key: created_at
To run the replication:
# Run the replication configuration
sling run -r snowflake_to_postgres.yaml
The replication YAML approach offers several advantages:
- Version control for your data transfer configurations
- Support for multiple streams in a single configuration
For more details about replication configuration, check out:
If PostgreSQL is your hub for several sources, the SQL Server to PostgreSQL guide shows the same incremental setup against a different source database.
Sling Platform: UI-Based Management
While the CLI is powerful for individual operations and automation, Sling also offers a comprehensive platform with a user-friendly interface for managing your data transfers. The Sling Platform provides:
Connection Management
The platform offers a centralized interface for managing all your database connections. You can easily:
- Configure and test connections
- Monitor connection status
- Manage credentials securely
- Share connections across your team

Visual Replication Editor
The platform includes a visual editor for creating and managing replication configurations:
- Intuitive interface for defining streams
- Syntax highlighting for YAML configurations
- Real-time validation
- Version control integration

Execution Monitoring
Monitor your data transfers in real-time:
- View detailed execution logs
- Track progress and performance metrics
- Identify and troubleshoot issues
- Set up alerts and notifications
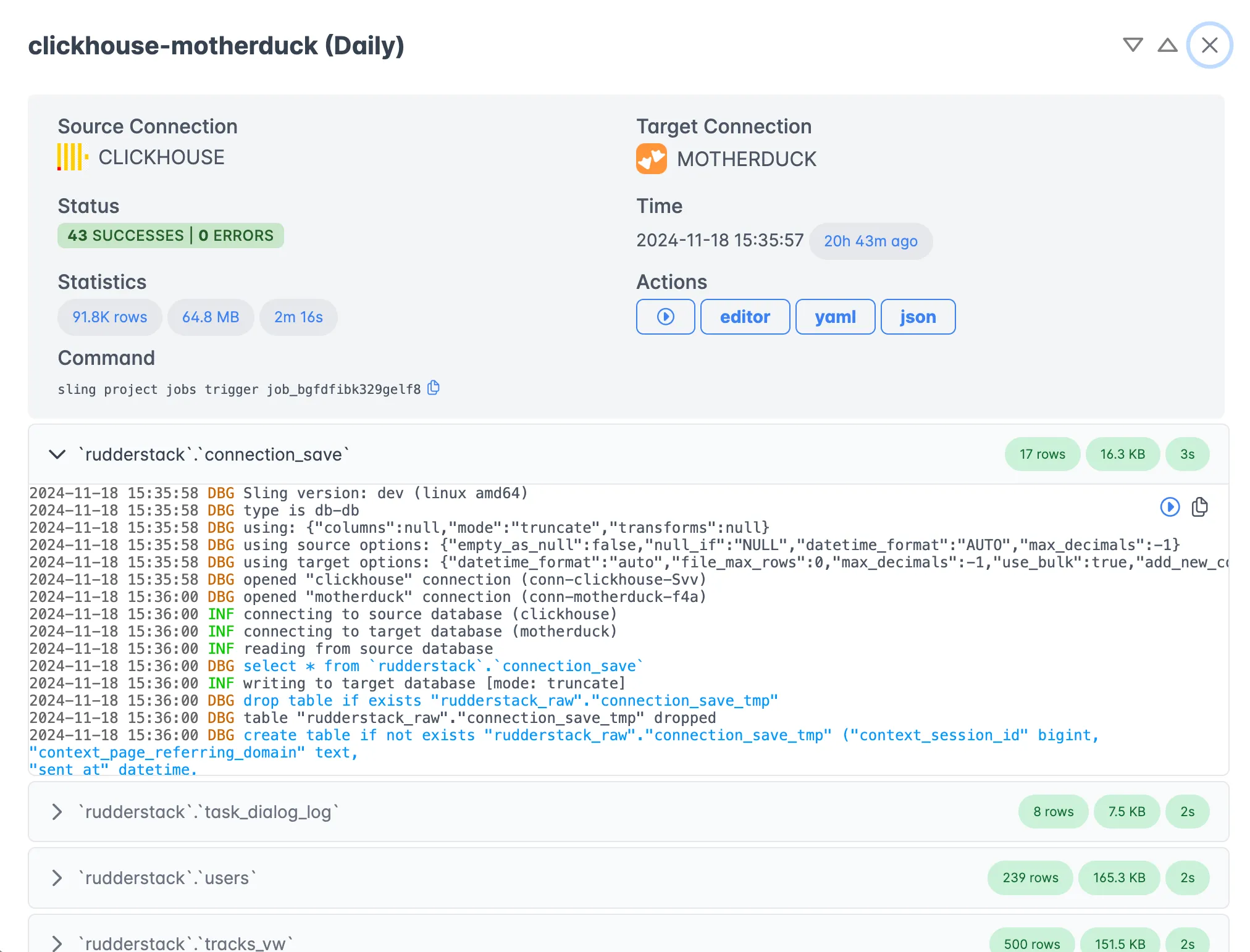
The Sling Platform is particularly useful for teams that need:
- Centralized management of data pipelines
- Visual monitoring and troubleshooting
- Collaboration features
- Audit trails and logging
- Scheduled executions
To get started with the Sling Platform, visit the Getting Started Guide.
Next Steps
Now that you’ve learned how to transfer data from Snowflake to PostgreSQL using Sling, here are some resources to help you go further:
FAQ
How does Sling decide which Snowflake columns and types map to PostgreSQL?
Sling reads the column metadata from Snowflake and picks the closest native PostgreSQL type for each one. If a default mapping isn’t what you want, define the column under the columns key in your stream and Sling uses that instead.
Can I move only part of a Snowflake table to PostgreSQL?
Yes. Use the select key to pick specific columns, or write a sql key with a full query when you need joins or filters. Both work per stream inside a replication file.
How do I keep PostgreSQL in sync with Snowflake on a schedule?
Run the same replication file in incremental mode with an update_key, then trigger it on a schedule with cron, an orchestrator, or the Sling Platform. Each run pulls only the rows that changed since the previous one.
Does pulling data out of Snowflake cost compute credits?
Yes. Every query Sling runs uses a Snowflake warehouse, so it burns credits like any other query. Narrowing columns with select and running in incremental mode keeps the scanned data, and the credit cost, down.
What happens when a new column appears in the Snowflake table?
Set add_new_columns: true under target_options and Sling adds the new column to PostgreSQL on the next run rather than erroring out. Leave it off and an unexpected column stops the run.
Can Sling handle Snowflake VARIANT or semi-structured columns?
Yes. Sling reads VARIANT, OBJECT, and ARRAY columns and loads them into PostgreSQL, usually as jsonb. If you need a different target type, set it under the columns key for that stream.
Whether you choose to use the CLI for automation or the Platform for visual management, Sling provides a robust solution for your data transfer needs. The combination of simple configuration, powerful features, and flexible deployment options makes it an excellent choice for building reliable data pipelines between Snowflake and PostgreSQL.