Sling Data Platform: Web-Based Data Integration
Using the Sling Platform is the easiest way to develop, test and manage your Sling jobs.
Pipeline without the headache
Connect an Agent
The sling agent can run anywhere (Mac, Linux or Windows), and waits for data jobs.
Add your Connections
Use the same env.yaml to easily define your connections.
Run Sling Jobs
Schedule your replications and get alerted for specific status.
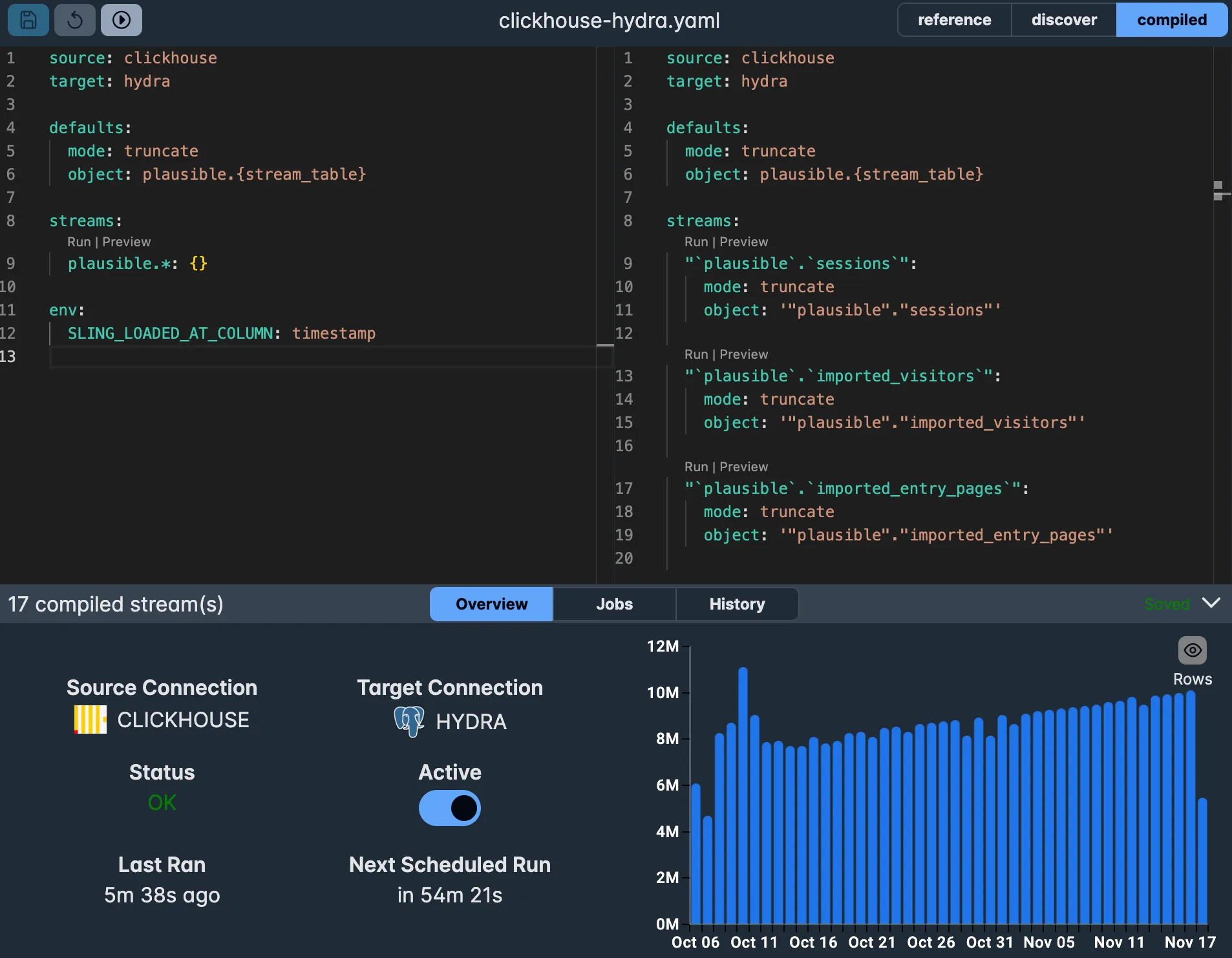
Built-in Editor (IDE)
With the included Editor, you can see your replications compiled live, as well as discover streams.
Parallel Stream Runs
With an agent, you can run your replication streams in parallel, allowing you to fully utilize your machine's resources.
Multiple Projects
Each project defines a specific workspace for your agents, connections and jobs. You can have an unlimited number of projects.
Schema Migration
Migrate primary keys, foreign keys, indexes, auto-increment columns, defaults, nullable constraints, and descriptions between databases automatically. Available on the Advanced plan.
Observability / Monitoring
Monitor your tables and files for volume, existence, freshness, and schema changes, all with a YAML file.
Use Hooks
Hooks can be used to trigger actions before or after a replication stream. Hook types include: query, check, notify, http, and more.
Change Data Capture (CDC)
Continuously replicate row-level changes by reading the database transaction log. Captures inserts, updates, and deletes with resumable initial loads and incremental sync. Available on the Advanced plan.
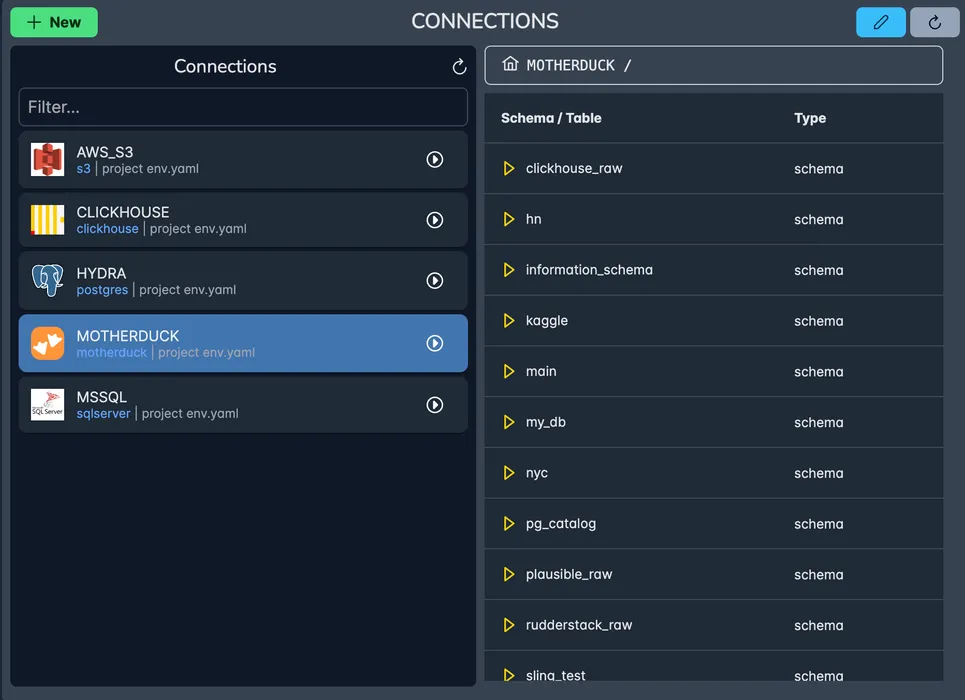
Explore your Data
Your can easily explore to see what files, folders or tables/schemas are present in your connection. You can even Preview the data before using it in a pipeline.
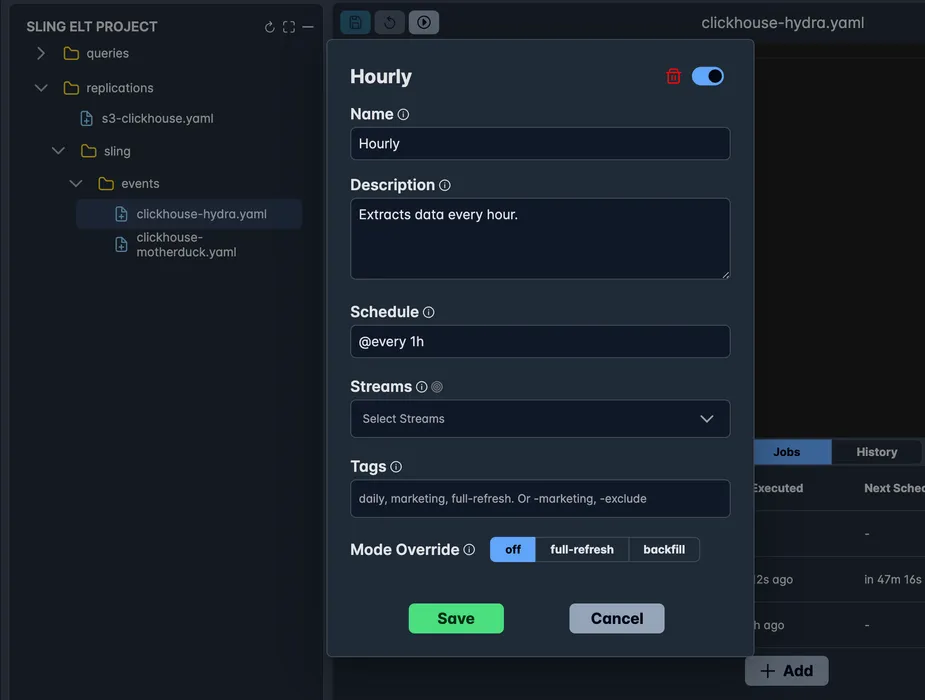
Define Jobs
Many ways to customize jobs, including running specific streams, tags, overriding the mode to full-refresh / backfill. And more.
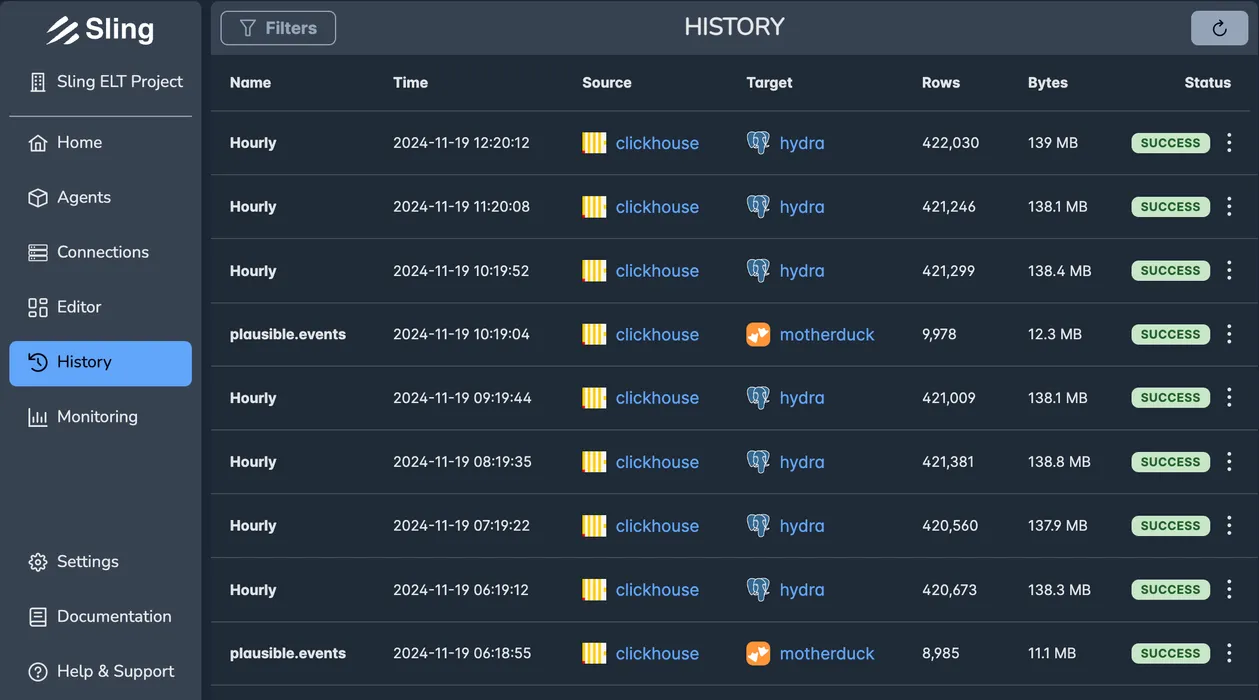
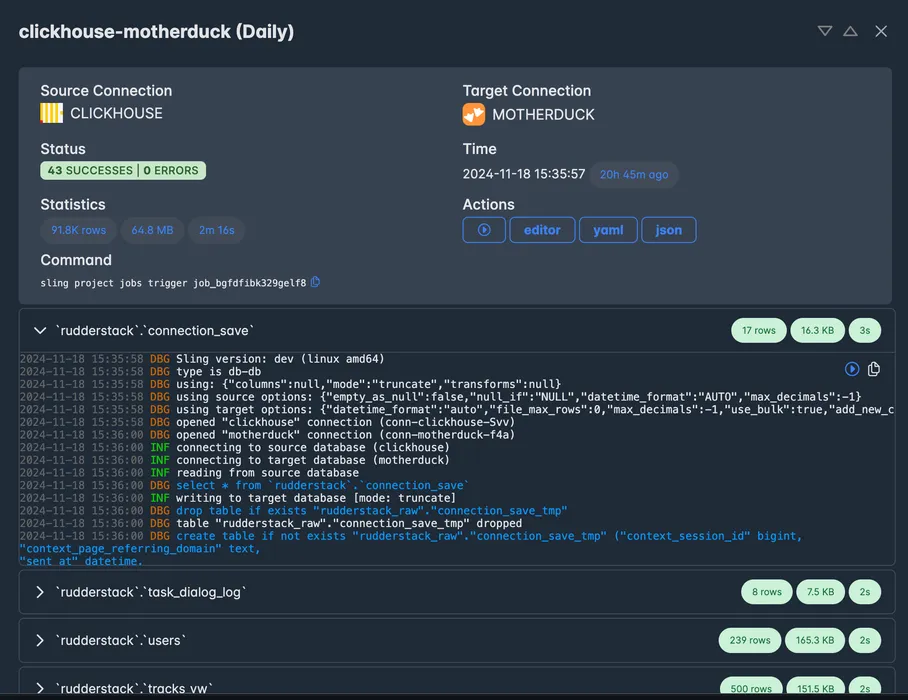
See Historical Logs
The history view lets you see history details such as number of rows / bytes transferred, duration, status in a tabular fashion.
See Job Run Details
The execution panel lets you see details such as number of rows / bytes transferred, duration, status and debug logs.
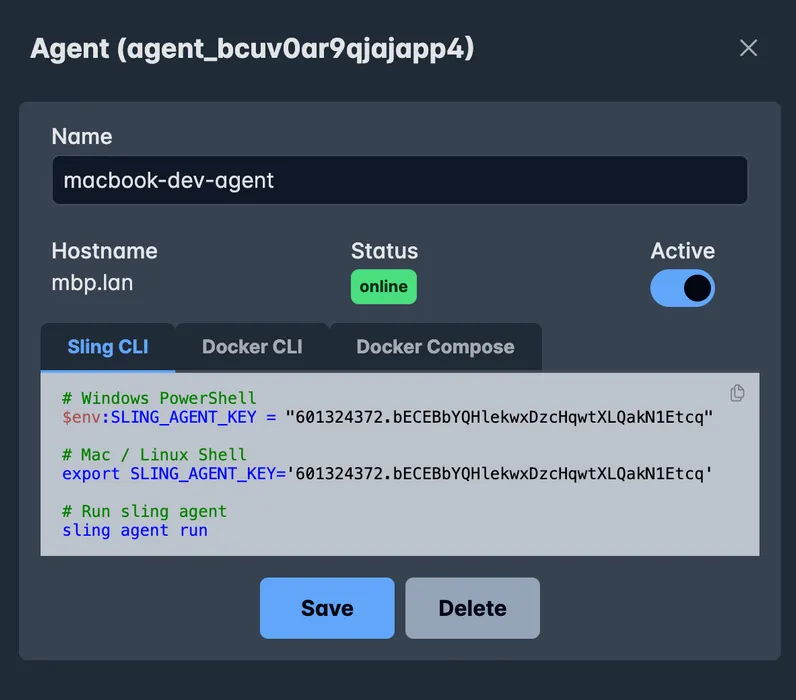
Manage Agents
The UI allows you to manage development & production agent as well as seeing their status. You get notified if any issues arise.
Transparent and Predictable Pricing
We believe in simple and predictable pricing. No hidden costs, no surprises. Scroll down to learn more about the Sling Agent and our pricing structure.
Free
$0
(free)- Incremental & Backfill Mode Incremental mode loads only new or updated data, while backfill mode loads data from a specified date range. Other available modes include: full-refresh, truncate and snapshot.
- Wildcard Selection Allows the use of wildcard characters in selection criteria, enabling more flexible selections of streams (source tables or files).
- Runtime & Custom Variables Support for both runtime and custom variables that can be used in YAML configurations, enabling powerful scaling and automation.
- Schema Evolution Ability to detect schema changes and automatically updates the target schema to match the source schema, ensuring compatibility and preventing errors.
- Custom Table DDL Allows the definition of custom Data Definition Language (DDL) for target table creation.
- Smart Editor (IDE) You can use the editor to preview data, validate for errors, as well as compile your replications live.
Standard
$99 / mo
- Incremental & Backfill Mode Incremental mode loads only new or updated data, while backfill mode loads data from a specified date range. Other available modes include: full-refresh, truncate and snapshot.
- Wildcard Selection Allows the use of wildcard characters in selection criteria, enabling more flexible selections of streams (source tables or files).
- Runtime & Custom Variables Support for both runtime and custom variables that can be used in YAML configurations, enabling powerful scaling and automation.
- Schema Evolution Ability to detect schema changes and automatically updates the target schema to match the source schema, ensuring compatibility and preventing errors.
- Custom Table DDL Allows the definition of custom Data Definition Language (DDL) for target table creation.
- Smart Editor (IDE) You can use the editor to preview data, validate for errors, as well as compile your replications live.
- Alerting (Email, Slack, MS Teams) You can setup alerts to be notified when certain conditions are met, such as: error, warning, or success.
- API Sources Extract data from any REST API with YAML-based specifications. Supports pagination, authentication, and incremental sync.
- Parallel Streams & Retries Process data faster with parallel streams and automatic retries for failed operations.
- Stream Chunking Break down large datasets into manageable chunks with time-based, numeric, or count-based partitioning.
- Capture Deletes Track and replicate deleted records with CDC-like functionality.
- Transforms Use transforms including: column hashing, encoding/decoding, uuid parsing, cleaning accents, and more.
- Pipelines & Hooks Create complex workflows with HTTP requests, SQL queries, file operations, and custom logic. Hooks can be triggered before or after a replication stream.
- OpenTelemetry Logging Export structured logs to any OTLP endpoint for centralized observability with Grafana, Datadog, and more.
- Production Agents A production agent enables scheduled jobs. You can tie a production agent to a single project. See below for details.(1)
Advanced
$249 / mo
- Incremental & Backfill Mode Incremental mode loads only new or updated data, while backfill mode loads data from a specified date range. Other available modes include: full-refresh, truncate and snapshot.
- Wildcard Selection Allows the use of wildcard characters in selection criteria, enabling more flexible selections of streams (source tables or files).
- Runtime & Custom Variables Support for both runtime and custom variables that can be used in YAML configurations, enabling powerful scaling and automation.
- Schema Evolution Ability to detect schema changes and automatically updates the target schema to match the source schema, ensuring compatibility and preventing errors.
- Custom Table DDL Allows the definition of custom Data Definition Language (DDL) for target table creation.
- Smart Editor (IDE) You can use the editor to preview data, validate for errors, as well as compile your replications live.
- Alerting (Email, Slack, MS Teams) You can setup alerts to be notified when certain conditions are met, such as: error, warning, or success.
- API Sources Extract data from any REST API with YAML-based specifications. Supports pagination, authentication, and incremental sync.
- Parallel Streams & Retries Process data faster with parallel streams and automatic retries for failed operations.
- Stream Chunking Break down large datasets into manageable chunks with time-based, numeric, or count-based partitioning.
- Capture Deletes Track and replicate deleted records with CDC-like functionality.
- Transforms Use transforms including: column hashing, encoding/decoding, uuid parsing, cleaning accents, and more.
- Pipelines & Hooks Create complex workflows with HTTP requests, SQL queries, file operations, and custom logic. Hooks can be triggered before or after a replication stream.
- OpenTelemetry Logging Export structured logs to any OTLP endpoint for centralized observability with Grafana, Datadog, and more.
- Production Agents A production agent enables scheduled jobs. You can tie a production agent to a single project. See below for details.(3+)
- Platform Self-Hosting The Advanced Plan allows you to optionally host the whole platform in your private network, allowing you full control & security.
- Git Integration Connect your project to a Git repository for version control, collaboration, and CI/CD workflows. Sync your pipelines and configurations with GitHub, GitLab, or Bitbucket.
- Change Data Capture (CDC) Continuously replicate row-level changes (inserts, updates, deletes) by reading the database's transaction log.
- Schema Migration Migrate primary keys, foreign keys, indexes, auto-increment columns, defaults, nullable constraints, and table/column descriptions between databases automatically.
- User Roles Define granular access controls with custom user roles and permissions. Control who can view, edit, create, or delete agents, connections, data pipelines and change settings across your project.
- Audit Logs Comprehensive logging and tracking of all platform activities, user actions, and data operations for compliance and security monitoring.
- Observability / Monitoring This allows monitoring of volume, existence, freshness, and schema changes, as well as historical runs, over time, for database and file objects. Alert rules can be setup for any of these metrics.
- Priority support
- Premium Support (Available)
CLI Core Features The Sling CLI is free forever and available for download. Run it on any machine.
Incremental & Backfill Mode Incremental mode loads only new or updated data, while backfill mode loads data from a specified date range. Other available modes include: full-refresh, truncate and snapshot.
Wildcard Selection Allows the use of wildcard characters in selection criteria, enabling more flexible selections of streams (source tables or files).
Runtime & Custom Variables Support for both runtime and custom variables that can be used in YAML configurations, enabling powerful scaling and automation.
Schema Evolution Ability to detect schema changes and automatically updates the target schema to match the source schema, ensuring compatibility and preventing errors.
Custom Table DDL Allows the definition of custom Data Definition Language (DDL) for target table creation.
Standard Features
Smart Editor (IDE) You can use the editor to preview data, validate for errors, as well as compile your replications live.
Alerting (Email, Slack, MS Teams) You can setup alerts to be notified when certain conditions are met, such as: error, warning, or success.
API Sources Extract data from any REST API with YAML-based specifications. Supports pagination, authentication, and incremental sync.
Parallel Streams & Retries Process data faster with parallel streams and automatic retries for failed operations.
Stream Chunking Break down large datasets into manageable chunks with time-based, numeric, or count-based partitioning.
Capture Deletes Track and replicate deleted records with CDC-like functionality.
Transforms Use transforms including: column hashing, encoding/decoding, uuid parsing, cleaning accents, and more.
Pipelines & Hooks Create complex workflows with HTTP requests, SQL queries, file operations, and custom logic. Hooks can be triggered before or after a replication stream.
OpenTelemetry Logging Export structured logs to any OTLP endpoint for centralized observability with Grafana, Datadog, and more.
Production Agents A production agent enables scheduled jobs. You can tie a production agent to a single project. See below for details.
Advanced Features
Platform Self-Hosting The Advanced Plan allows you to optionally host the whole platform in your private network, allowing you full control & security.
Git Integration Connect your project to a Git repository for version control, collaboration, and CI/CD workflows. Sync your pipelines and configurations with GitHub, GitLab, or Bitbucket.
Change Data Capture (CDC) Continuously replicate row-level changes (inserts, updates, deletes) by reading the database's transaction log.
Schema Migration Migrate primary keys, foreign keys, indexes, auto-increment columns, defaults, nullable constraints, and table/column descriptions between databases automatically.
User Roles Define granular access controls with custom user roles and permissions. Control who can view, edit, create, or delete agents, connections, data pipelines and change settings across your project.
Audit Logs Comprehensive logging and tracking of all platform activities, user actions, and data operations for compliance and security monitoring.
Observability / Monitoring This allows monitoring of volume, existence, freshness, and schema changes, as well as historical runs, over time, for database and file objects. Alert rules can be setup for any of these metrics.
Support
Priority support
Premium Support
Frequently Asked Questions
What is an agent?
Can I self-host my agent? What about Cloud agents?
What about my Connection Credentials?
I'm interested in features of a paid Plan, but want to use the Sling CLI without an Agent
What if I want to pay yearly?
How does the agent work?
How do development and production agents differ?
How many production agents will I need?
Can I self-host the control server along with the agent?